在如今机器的 CPU 都是多核的背景下,Node 的单线程设计已经没法更充分的" 压榨" 机器性能了。所以从 v0.8 开始,Node 新增了一个内置模块——“cluster”,故名思议,它可以通过一个父进程管理一坨子进程的方式来实现集群的功能。
快速上手
使用十分的简单,如下
稍微解释下,通过 isMaster 属性,判断是否 Master 进程,是则 fork 子进程,否则启动一个 server。每个 HTTP server 都能监听到同一个端口。
但是在实际项目中,我们的启动代码一般都已经封装在了 app.js 中,要把整块启动逻辑嵌在上面的 if else 中实在不优雅。 所以,我们可以这样:
简单之处就在于原本的应用逻辑根本不需要知道自己是在集群还是单边。(当然,如果应用在内存中维护了某些状态,比如 session,就需要运用某些机制来共享了,这里不详说)
常用 API
cluster 模块提供了一大坨事件和方法,这里挑一些常用的说明下,详细的请参考官方文档。
cluster.setupMaster([settings])
setupMaster 用来改变默认设置,只能被调用一次,调用后,配置会存在且冻结在 cluster.settings 里。配置只会影响 fork 时的行为,实际上这些选项就是传给 fork 用的,有兴趣的同学可以去对照 child_process.fork() 的参数。
具体有如下选项:
- execArgv Node 执行时的变量数组,传递给 node(默认为 process.execArgv)。
- exec 执行的文件,配置后就不需要像最开始的例子,在代码里 require 目标文件了(默认为 process.argv[1])。
- args 传递给 worker 的变量数组(默认为 process.argv.slice(2)))。
- silent 是否禁止打印内容(默认为 false)。
- uid 设置进程的用户 ID。
- gid 设置进程的组 ID。
Event: fork 和 online
当一个新的 worker 被 fork 时就会触发 fork 事件,而在 worker 启动时才会触发 online 事件,所以 fork 先触发,online 后触发。
可以在这两个事件的 callback 里做些初始化的逻辑,也可以在这时向 master 报告:“ 我起来了!”。
Event: exit
当任何一个 worker 停掉都会触发 exit 事件,可以在回调里增加 fork 动作重启。
通过 worker.suicide 来判断,worker 是意外中断还是主动停止的(在 worker 中调用 kill 和 disconnect 方法,视作 suide。)。
cluster.worker 和 cluster.workers
前者是一份 worker 对象的引用,只能在 worker 里使用。
后者是 master 下对当前可用 worker 的一个 Object,key 为 worker id,注意,当 worker 已经 exit 或 disconnect 后就不会在这个 object 里了。
Event: message
message 事件可以用来做 master 和 worker 的通信机制。 这里是个例子 。
利用这套机制,可以用来实现不间断重启,代码。
文章最开始的例子有个问题,尤其是运行在生产环境还不够健壮:如果某个 worker 因为意外“ 宕机” 了,代码并没有任何处理,这时如果我们重启应用又会造成服务中断。利用这些 API 就可以利用事件监听的方式做相应处理。
原理
每个 worker 进程通过使用 child_process.fork() 函数,基于 IPC(Inter-Process Communication,进程间通信),实现与 master 进程间通信。
什么是 fork,Linux API 给了如下解释
fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.
The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect the other.
我们可以看到,fork 出的子进程拥有和父进程一致的数据空间、堆、栈等资源(fork 当时),但是是独立的,也就是说二者不能共享这些存储空间。 那我们直接用 fork 自己实现不就行了,干嘛需要 cluster 呢。
“ 这样的方式仅仅实现了多进程。多进程运行还涉及父子进程通信,子进程管理,以及负载均衡等问题,这些特性 cluster 帮你实现了。”
这里再说下 cluster 的负载均衡。Node.js v0.11.2+的 cluster 模块使用了 round-robin 调度算法做负载均衡,新连接由主进程接受,然后由它选择一个可用的 worker 把连接交出去,说白了就是轮转法。算法很简单,但据官方说法,实测很高效。
注意:在 windows 平台,默认使用的是 IOCP,官方文档说一旦解决了分发 handle 对象的性能问题,就会改为 RR 算法(没有时间表。。)
如果想用操作系统指定的算法,可以在 fork 新 worker 之前或者 setupMaster() 之前指定如下代码:
或者通过环境变量的方式改变
或在启动 Node 时指定
使用 pm2 实现 cluster
pm2 是一个现网进程管理的工具,可以做到不间断重启、负载均衡、集群管理等,比 forever 更强大。利用 pm2 可以做到 no code but just config 实现应用的 cluster。
安装 pm2 什么的这里就不赘述了。用 pm2 启动时,通过-i 指定 worker 的数量即可。如果 worker 挂了,pm2 会自动立刻重启,各种简单省心。
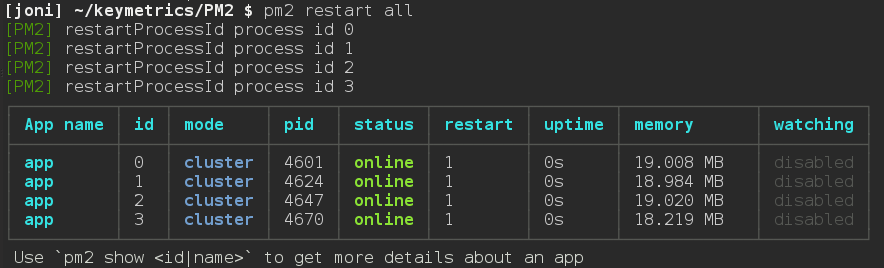
也可以在应用运行时,改变 worker 的数量,如下图
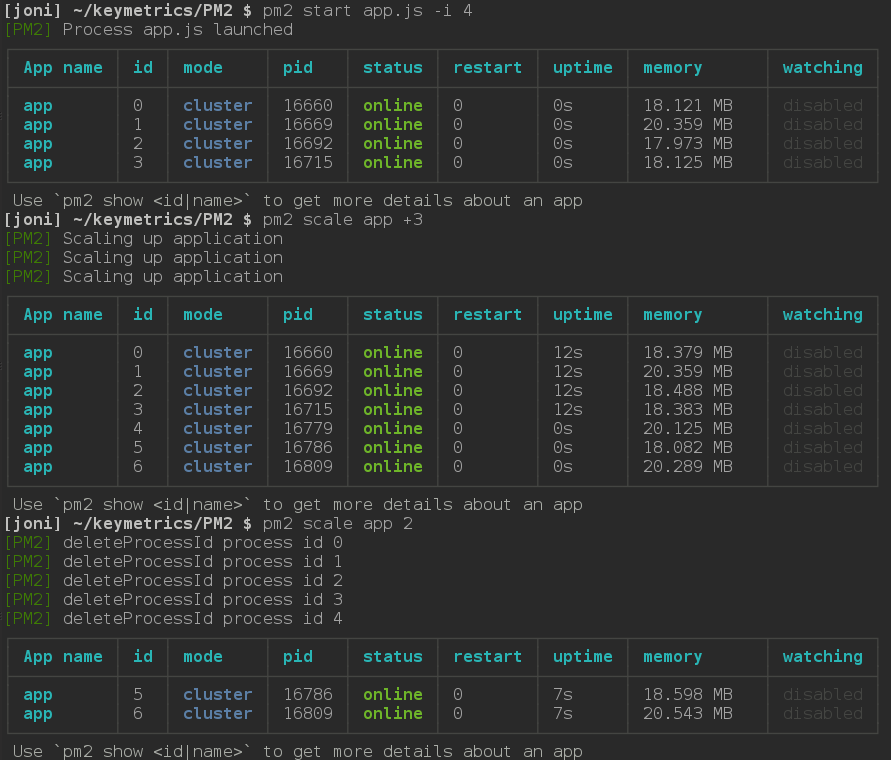
更多的使用方法,可以去 github 上慢慢看(说句题外话,如果有类似 PM2,甚至更好的 PM 工具,欢迎在评论里回复^_^)。
多机器集群
cluster 适用于在单台机器上,如果应用的流量巨大,多机器是必然的。这时,反向代理就派上用场了,我们可以用 node 来写反向代理的服务(比如用 http-proxy),好处是可以保持工程师技术栈的统一,不过生产环境,我们用的更多的还是 nginx,这里就不多介绍了。

sailor 2017 年 10 月 26 日
代码里的小于号被转义了。
helm 2017 年 7 月 4 日
提个意见,进入网站后首页是一个大大的 Alloyteam, 过了一会才消失 (感觉在 onload 后), 不可否认,你们团队很厉害,但是这样设计是不是有点冗余?毕竟用户点进来第一眼想看的还是文章。
(![]+[])[+[]]+(!![]+[])[+!+[]+!+[]+!+[]] 2016 年 5 月 17 日
学习了,赞!
雪糕妹妹 2015 年 10 月 27 日
叹气是最浪费时间的事情,哭泣是最浪费力气的行径。
雪糕妹妹 2015 年 10 月 27 日
不错, 顶的人不多啊,快点继续
い用生命叙述故事 2015 年 9 月 1 日
赞~有个问题就是 fork 之后子进程会在父进程那里留下子进程对象,eg:var child = fork(‘./client’); 能否让 child 拥有单独的键盘输入流呢??而不是父进程接收到 stdin 然后转递给 child