上次文章介绍了如何用 webgl 快速创建一个自己的小世界,在我们入门 webgl 之后,并且可以用原生 webgl 写 demo 越来越复杂之后,大家可能会纠结一点:就是我使用 webgl 的姿势对不对。因为 webgl 可以操控 shader 加上超底层 API,带来了一个现象就是同样一个东西,可以有多种的实现方式,而此时我们该如何选择呢?这篇文章将稍微深入一点 webgl,给大家介绍一点 webgl 的优化知识。
讲 webgl 优化之前我们先简单回忆一下 canvas2D 的优化,常用的 display list、动态区域重绘等等。用 canvas2D 多的同学应该对以上的优化或多或少都有了解,但是你对 webgl 的优化了解么,如果不了解的话往下看就对了~这里会先从底层图像是如何渲染到屏幕上开始,逐步开始我们的 webgl 优化。
gpu 如何渲染出一个物体
先看一个简单的球的例子,下面是用 webgl 画出来的一个球,加上了一点光的效果,代码很简单,这里就不展开说了。
一个球
这个球是一个简单的 3D 模型,也没有复杂的一些变化,所以例子中的球性能很好,看 FPS 值稳定在 60。后面我们会尝试让它变得复杂起来,然后进行一些优化,不过这一节我们得先了解渲染的原理,知其根本才能知道优化的原理。
我们都知道 webgl 与着色器是密不可分的关系,webgl 当中有顶点着色器和片段着色器,下面用一张图来简单说明下一个物体由 0 到 1 生成的过程。
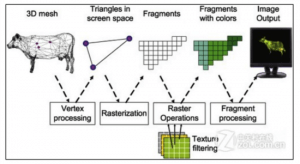
0 就是起点,对应图上面的 3D mesh,在程序中这个就是 3D 顶点信息
1 就是终点,对应图上面的 Image Output,此时已经渲染到屏幕上了
我们重点是关注中间那三个阶段,第一个是一个标准的三角形,甚至三角形上面用三个圈指明了三个点,再加上 vertex 关键字,可以很明白的知道是顶点着色器处理的阶段,图翻译为大白话就是:
我们将顶点信息传给顶点着色器 (drawElements/drawArray),然后着色器将顶点信息处理并开始画出三角形 (gl_Position)
然后再看后两个图,很明显的 fragments 关键字指明了这是片元着色器阶段。Rasterization 是光栅化,从图上直观的看就是三角形用三条线表示变成了用像素表示,其实实际上也是如此,更详细的可以看下面地址,这里不进行展开。
如何理解光栅化-知乎
后面阶段是上色,可以用 textture 或者 color 都可以,反正统一以 rgba 的形式赋给 gl_FragColor
图中 vertexShader 会执行 3 次,而 fragmentShader 会执行 35 次 (有 35 个方块)
发现 fragmentShader 执行次数远远超过 vertexShader,此时机智的朋友们肯定就想到尽可能的将 fragmentShader 中的计算放在 vertexShader 中,但是能这样玩么?
强行去找还是能找到这样的场景的,比如说反射光。反射光的计算其实不是很复杂,但也稍微有一定的计算量,看核心代码
上面反射光代码就不细说了,核心就是内置的 reflect 方法。这段代码既可以放在 fragmentShader 中也可以放在 vertexShader 中,但是二者的结果有些不同,结果分别如下
放在 vertexShader 中
放在 fragmentShader 中
所以说这里的优化是有缺陷的,可以看到 vertexShader 中执行光计算和 fragmentShader 中执行生成的结果区别还是蛮大的。换言之如果想要实现真实反射光的效果,必须在 fragmentShader 中去计算。开头就说了这篇文章的主题在同样的一个效果,用什么方式是最优的,所以 continue~
gpu 计算能力很猛
上一节说了 gpu 渲染的原理,这里再随便说几个 gpu 相关的新闻
百度人工智能大规模采用 gpu,PhysX 碰撞检测使用 gpu 提速……种种类似的现象都表明了 gpu 在单纯的计算能力上是超过普通的 cpu,而我们关注一下前一节 shader 里面的代码
vertexShader
fragmentShader
可以发现逻辑语句很少,更多的都是计算,特别是矩阵的运算,两个 mat4 相乘通过 js 需要写成这样 (代码来自 glMatrix)
可以说相比普通的加减乘除来说矩阵相关的计算量还是有点大的,而 gpu 对矩阵的计算有过专门的优化,是非常快的
所以我们第一反应肯定就是能在 shader 中干的活就不要让 js 折腾啦,比如说前面代码中将 proMatrix/viewMatrix/modelMatrix 都放在 shader 中去计算。甚至将 modelMatrix 里面再区分成 moveMatrix 和 rotateMatrix 可以更好的去维护不是么~
但是了解 threejs 或者看其他学习资料的的同学肯定知道 threejs 会把这些计算放在 js 中去执行,这是为啥呢??比如下方代码 (节选自 webgl 编程指南)
vertexShader 中
javascript 中
这里居然把 proMatrix/viewMatrix/modelMatrix 全部在 js 中计算好,然后传入到 shader 中去,为什么要这样呢?
结合第一节我们看下vertexShader执行的次数是和顶点有关系的,而每个顶点都需要做对象坐标->世界坐标->眼睛坐标的变换,如果传入三个顶点,就代表 gpu 需要将 proMatrix * viewMatrix * modelMatrix 计算三次,而如果我们在 js 中就计算好,当作一个矩阵传给 gpu,则是极好的。js 中虽然计算起来相较 gpu 慢,但是胜在次数少啊。
看下面两个结果
在 shader 中计算
在 js 中计算
第一个是将矩阵都传入给 gpu 去计算的,我这边看到 FPS 维持在 50 左右
第二个是将部分矩阵计算在 js 中完成的,我这边看到 FPS 维持在 60 样的
这里用的 180 个球,如果球的数量更大,区别还可以更加明显。所以说 gpu 计算虽好,但不要滥用呦~
js 与 shader 交互的成本
动画就是画一个静态场景然后擦掉接着画一个新的,重复不断。第一节中我们用的是 setInterval 去执行的,每一个 tick 中我们必须的操作就是更新 shader 中的 attribute 或者 uniform,这些操作是很耗时的,因为是 js 和 glsl 程序去沟通,此时我们想一想,有没有什么可以优化的地方呢?
比如有一个场景,同样是一个球,这个球的材质颜色比较特殊

x,y 方向上都有着渐变,不再是第一节上面一个色的了,此时我们该怎么办?
首先分析一下这个这个球

总而言之就是水平和垂直方向都有渐变,如果按之前的逻辑扩展,就意味着我们得有多个 uniform 去标识
我们先尝试一下,用如下的代码,切换 uniform 的方式
使用切换 uniform 的方式
发现 FPS 在 40 左右,还是蛮卡的。然后我们考虑一下,卡顿在哪?
vertexShader 和 fragmentShader 执行的次数可以说都是一样的,但是 uniform4fv 和 drawElements 每一次 tick 中执行了多次,就代表着 js 与 shader 耗费了较大的时间。那我们应该如何优化呢?
核心在避免多次改变 uniform,比方说我们可以尝试用 attribute 去代替 uniform
看下结果怎样
使用 attribute 的方式
瞬间 FPS 就上去了对不~所以说灵活变通很重要,不能一味的死板,尽可能的减少 js 与 shader 的交互对性能的提高是大大有帮助的~
切换 program 的成本
上一节我们发现频繁切换切换 uniform 的开销比较大,有没有更大的呢?
当然有,那就是切换 program,我们把之前的例子用切换 program 的方式试下,直接看下面的例子
点击前慎重,可能会引起浏览器崩溃
切换 program
已经不需要关心 FPS 的了,可以直观的感觉到奇卡无比。切换 program 的成本应该是在 webgl 中开销是非常大的了,所以一定要少切换 program
这里说的是少切换 program,而不是说不要切换 program,从理论上来说可以单个 program 写完整个程序的呀,那什么时候又需要切换 program 呢?
program 的作用是代替 if else 语句,相当于把 if else 抽出来单独一个 program,所以就是如果一个 shader 里面的 if else 多到开销超过 program 的开销,此时我们就能选择用 program 啦。
当然这里的度有点难把握,需要开发者自己多尝试,结合实际情况进行选择。这里有一个关于选择 program 还是 if else 的讨论,感兴趣的同学可以看看
https://forums.khronos.org/showthread.php/7144-Performance-More-Shaderprograms-VS-IF-Statements-in-Shader
结语
我们这里从原理触发,尝试了 webgl 的一些优化~如果你有什么建议和疑惑~欢迎留言讨论~

小书童 2017 年 12 月 14 日
学习了!
bird 2017 年 8 月 15 日
好厉害