0. 前言
腾讯文档列表页在不久前经历了一次完全重构后,首屏速度其实已经是不错。但是我们仍然可以引入 SSR 来进一步加快速度。这篇文章就是用来记录和整理我最近实现 SSR 遇到的一些问题和思考。虽然其中有一些基础设施可能和腾讯或文档强相关,但是作为一篇涉及 Node、React 组件、性能、网络、docker 镜像 、云上部署、灰度和发布等内容的文章,仍然可以小小地作为参考或者相似需求的 Checklist。
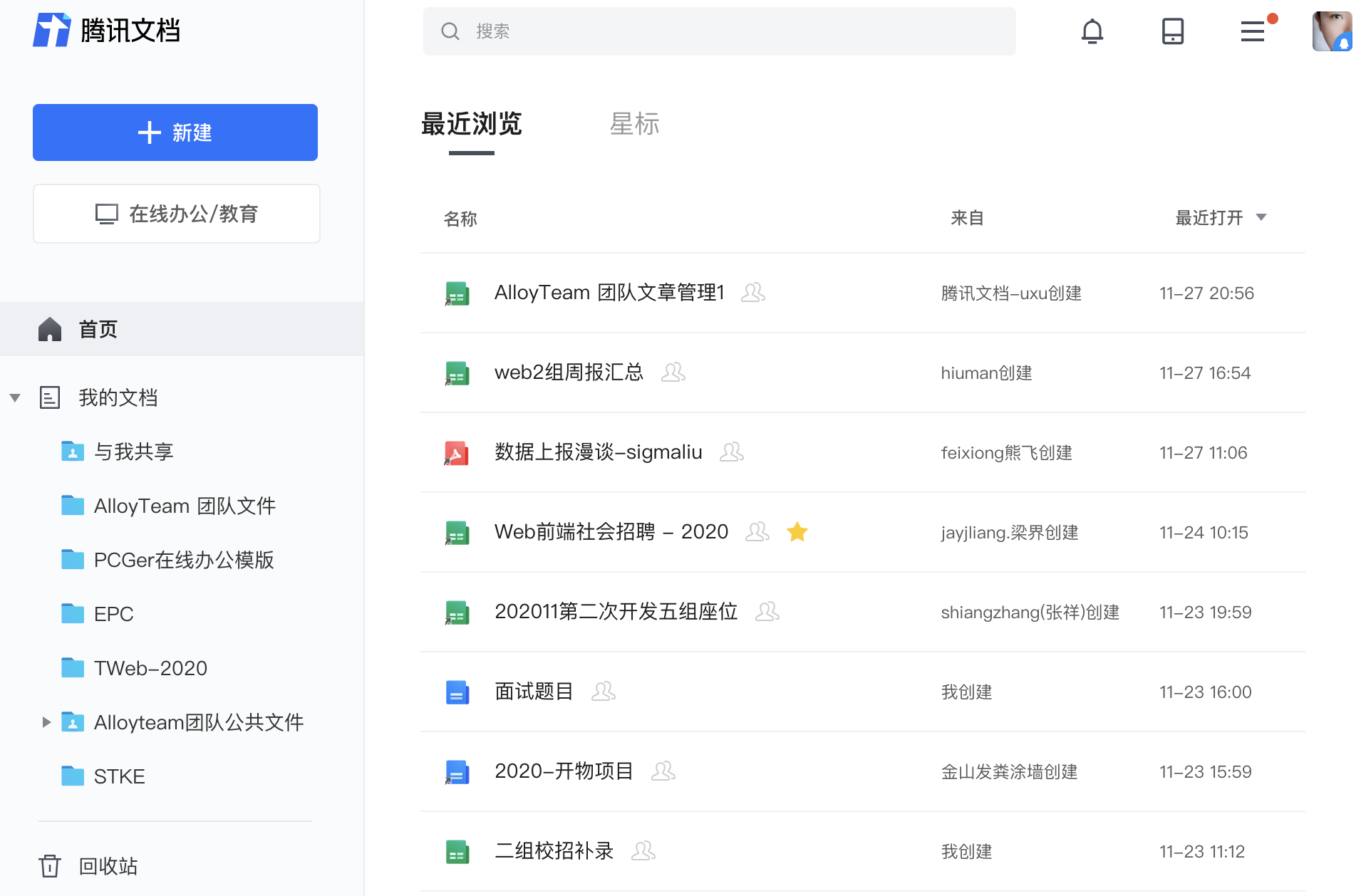
就是这样一个页面,内部逻辑复杂,优秀的重构同学做到了组件尽可能地复用,未压缩的编译后开发代码仍然有 14W 行,因此也不算标题党了。

1. 整体流程
1.1 CSR
我们回顾 CSR(客户端渲染)的流程
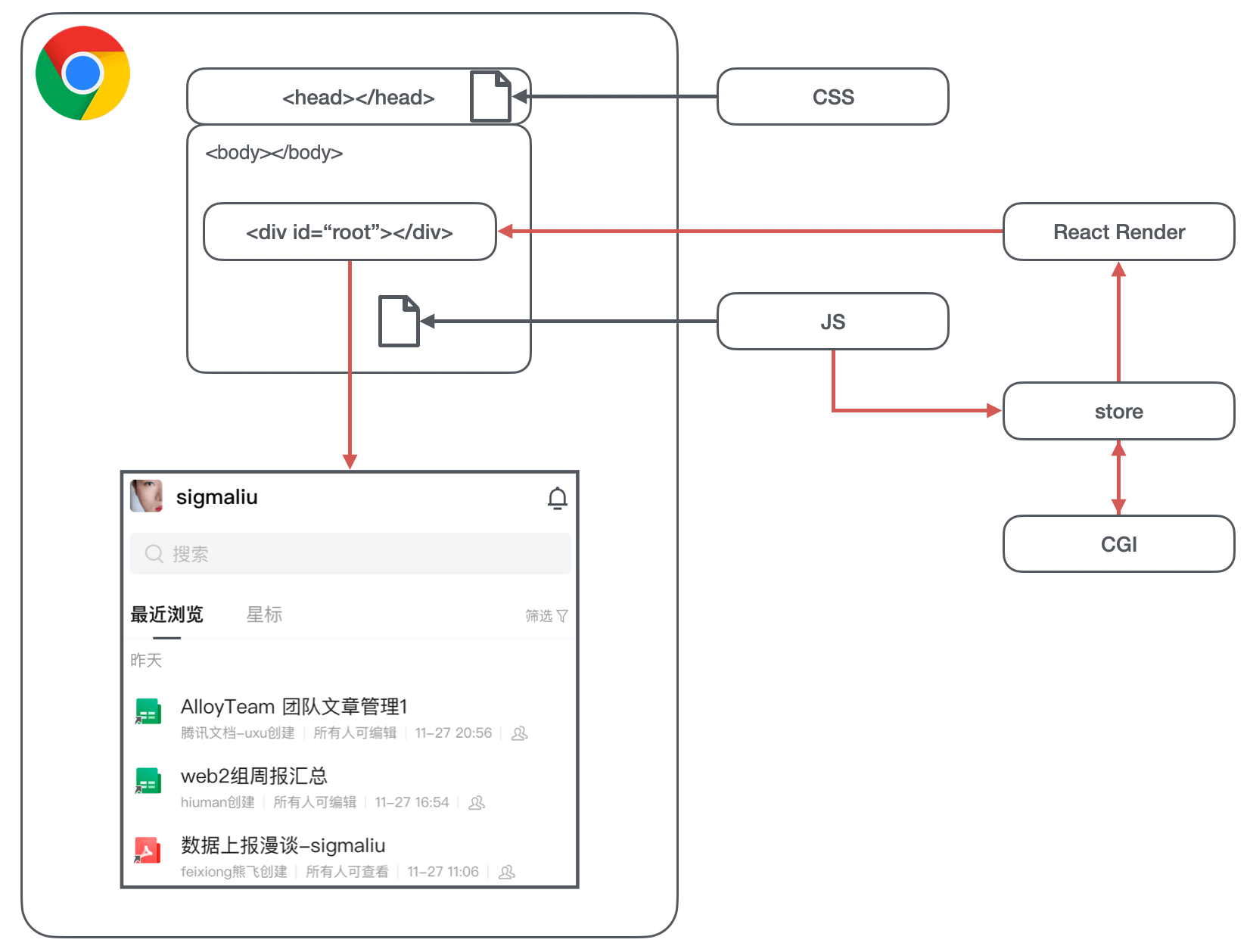
- 一个 React 应用,通常我们把 CSS 放在 head,有个 React 应用挂载的根节点空标签,以及 React 应用编译后的主体文件。浏览器在加载 HTML 后,加载 CSS 和 JS,到这时候为止,浏览器呈现给用户的仍然是个空白的页面。
- < 红色箭头部分> JS 开始执行,状态管理会初始化个 store,会先拿这个 store 去渲染页面,这时候页面开始渲染元素(白屏时间结束)。但是还没有列表的详细信息,也没有头像、用户名那些信息。
- 初始化 store 后会发起异步的 CGI 请求,在请求回来后会更新 store,触发 React 重新渲染页面,绑定事件,整个页面完全呈现(首屏时间结束)。
1.2 SSR
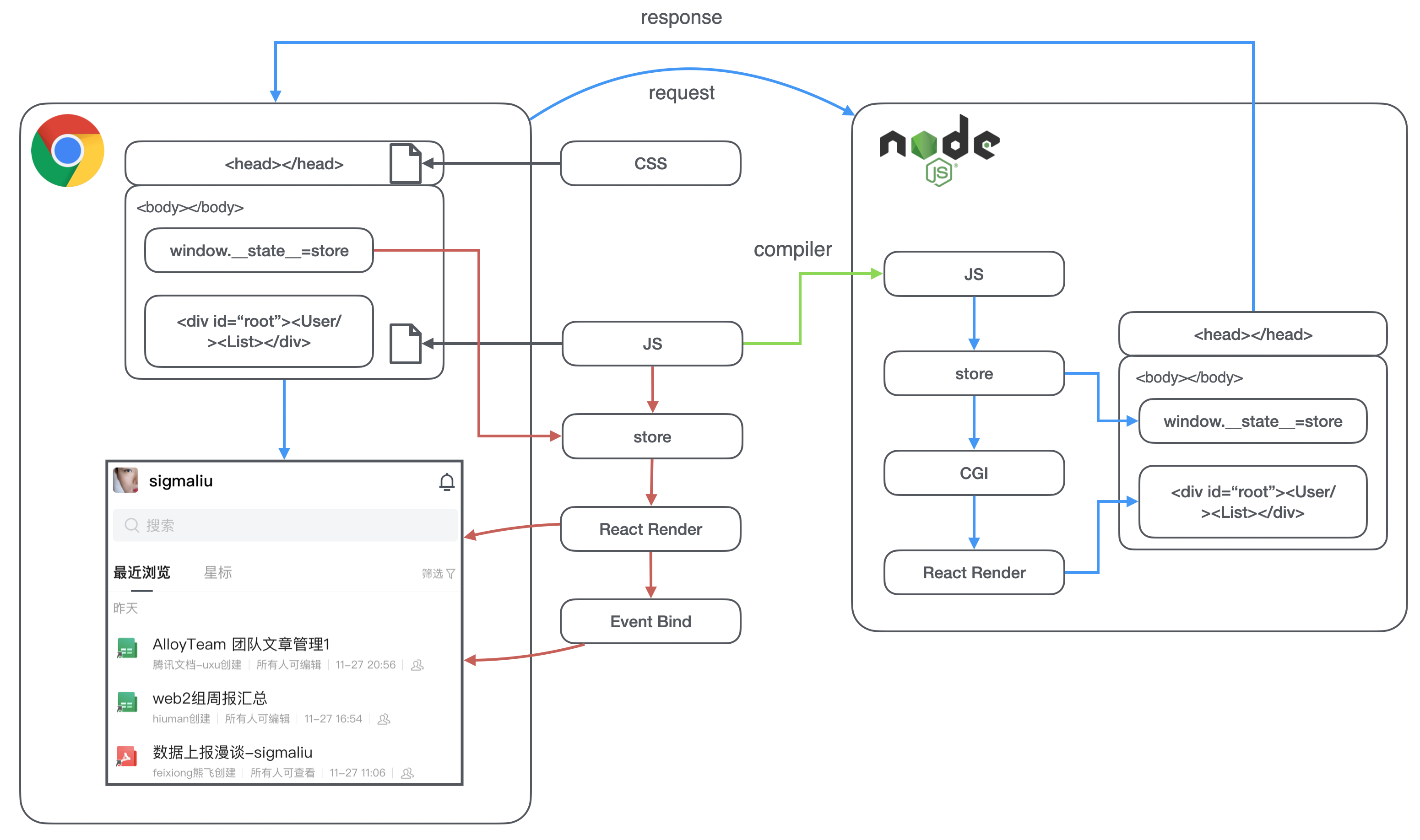
- < 绿色箭头部分> 首先我们复用原来的 React 组件编译出可以在 Node 环境下运行的文件,并且部署一个 Node 服务。
- < 蓝色箭头部分> 在浏览器发起 HTML 请求时,我们的 Node 服务会接收到请求。可以从请求里取出 HTTP 头部,Cookie 等信息。运行对应的 JS 文件,初始化 store,发起 CGI 请求填充数据,调用 React 渲染 DOM 节点(这里和 CSR 的差异在于我们得等 CGI 请求回来数据改变后再渲染,也就是需要的数据都准备好了再渲染)。
- 将渲染的 DOM 节点插入到原 React 应用根节点的内部,同时将 store 以全局变量的形式注入到文档里,返回最终的页面给浏览器。浏览器在拿到页面后,加上原来的 CSS,在 JS 下载下来之前,就已经能够渲染出完整的页面了(白屏时间结束、首屏时间结束)。
- < 红色箭头部分> JS 开始执行,拿服务端注入的数据初始化 store,渲染页面,绑定事件(可交互时间结束)(这里其实后面可能还有一些 CGI,因为有一些 CGI 是不适合放在服务端的,且不影响首页直出的页面,会放在客户端上加快首屏速度。这里的一个优化点在于我们将尽量避免在服务端有串行的 CGI 存在,比如需要先发起一个 CGI,等结果返回后才发起另外一个 CGI,因为这会将 SSR 完全拖垮一个 CGI 的速度)。
2. 入口文件
2.1 服务端入口文件
要把代码在 Node 下跑起来,首先要编译出文件来。除了原来的 CSR 代码外,我们创建一个 Node 端的入口文件,引入 CSR 的 React 组件。
(async () => {
const store = useStore();
await Promise.all([
store.dispatch.user.requestGetUserInfo(),
store.dispatch.list.refreshRecentOpenList(),
]);
const initialState = store.getState();
const initPropsDataHtml = getStateScriptTag(initialState);
const bodyHtml = ReactDOMServer.renderToString(
<Provider store={store}>
<ServerIndex />
</Provider>
);
// 回调函数,将结果返回的
TSRCALL.tsrRenderCallback(false, bodyHtml + initPropsDataHtml);
})();服务端的 store,Provider, reducer,ServerIndex 等都是复用的客户端的,这里的结构和以下客户端渲染的一致,只不过多了 renderToString 以及将结果返回的两部分。
2.2 客户端入口文件
相应的,客户端的入口文件做一点改动:
export default function App() {
const initialState = window.__initial_state__ || undefined;
const store = useStore(initialState);
// 额外判断数据是否完整的
const { getUserInfo, recentList } = isNeedToDispatchCGI(store);
useEffect(() => {
Promise.race([
getUserInfo && store.dispatch.user.requestGetUserInfo(),
store.dispatch.notification.requestGetNotifyNum(),
]).finally(async () => {
store.dispatch.banner.requestGetUserGrowthBanner();
recentList && store.dispatch.list.requestRecentOpenList();
});
}, []);
}主要是复用服务端注入到全局变量的数据以及 CGI 是否需要重发的判断。
2.3 代码编译
将服务端的代码编译成 Node 下运行的文件,最主要的就是设置 webpack 的 target: 'node' ,以及为了在复用的代码里区分服务端还是客户端,会注入编译变量。
new webpack.DefinePlugin({
__SERVER__: (process.env.RENDER_ENV === 'server'),
})其他的大部分保持和客户端的编译配置一样就 OK 了,一些细微的调整后面会说到。
3. 代码改造
将代码编译出来,但是先不管跑起来能否结果一致,能不报错大致跑出个 DOM 节点来又是另外一回事。
3.1 运行时差异
首先摆在我们前面的问题在于浏览器端和 Node 端运行环境的差异。就最基本的,window,document 在 Node 端是没有的,相应的,它们以下的好多方法就不能使用。 我们当然可以选择使用 jsdom 来模拟浏览器环境,以下是一个 demo:
const jsdom = require("jsdom");
const { JSDOM } = jsdom;
const { window } = new JSDOM(``, {
url: 'http://localhost',
});
global.localStorage = window.localStorage;
localStorage.setItem('AlloyTeam', 'NB');
console.log(localStorage.getItem('AlloyTeam'));
// NB但是当我使用的时候,有遇到不支持的 API,就需要去补 API。且在 Node 端跑预期之外的代码,生成的是否是预期的结果也是存疑,工作量也会较大,因此我选择用编译变量来屏蔽不支持的代码,以及在全局环境下注入很有限的变量(vm + context)。
3.2 非必需依赖
对于不支持 Node 环境的依赖模块来说,比如浏览器端的上报库,统一的打开窗口的库,模块动态加载库等,对首页直出是不需要的,可以选择配置 alias 并使用空函数代替防止调用报错或 ts 检查报错。
alias: {
src: path.resolve(projectDir, 'src'),
'@tencent/tencent-doc-report': getRewriteModule('./tencent-doc-report.ts'),
'@tencent/tencent_doc_open_url': getRewriteModule('./tencent-doc-open-url.ts'),
'script-loader': getRewriteModule('./script-loader.ts'),
'@tencent/docs-scenario-components-message-center': getRewriteModule('./message-center.ts'),
'@tencent/toggle-client-js': getRewriteModule('./tencent-client-js.ts'),
},例如里面的 script-loader(模块加载器,用来动态创建 <script> 标签注入 JS 模块的),整个模块屏蔽掉。
const anyFunc = (...args: any[]) => {};
export const ScriptLoader = {
init: anyFunc,
load: anyFunc,
listen: anyFunc,
dispatch: anyFunc,
loadRemote: anyFunc,
loadModule: anyFunc,
};3.3 必需依赖
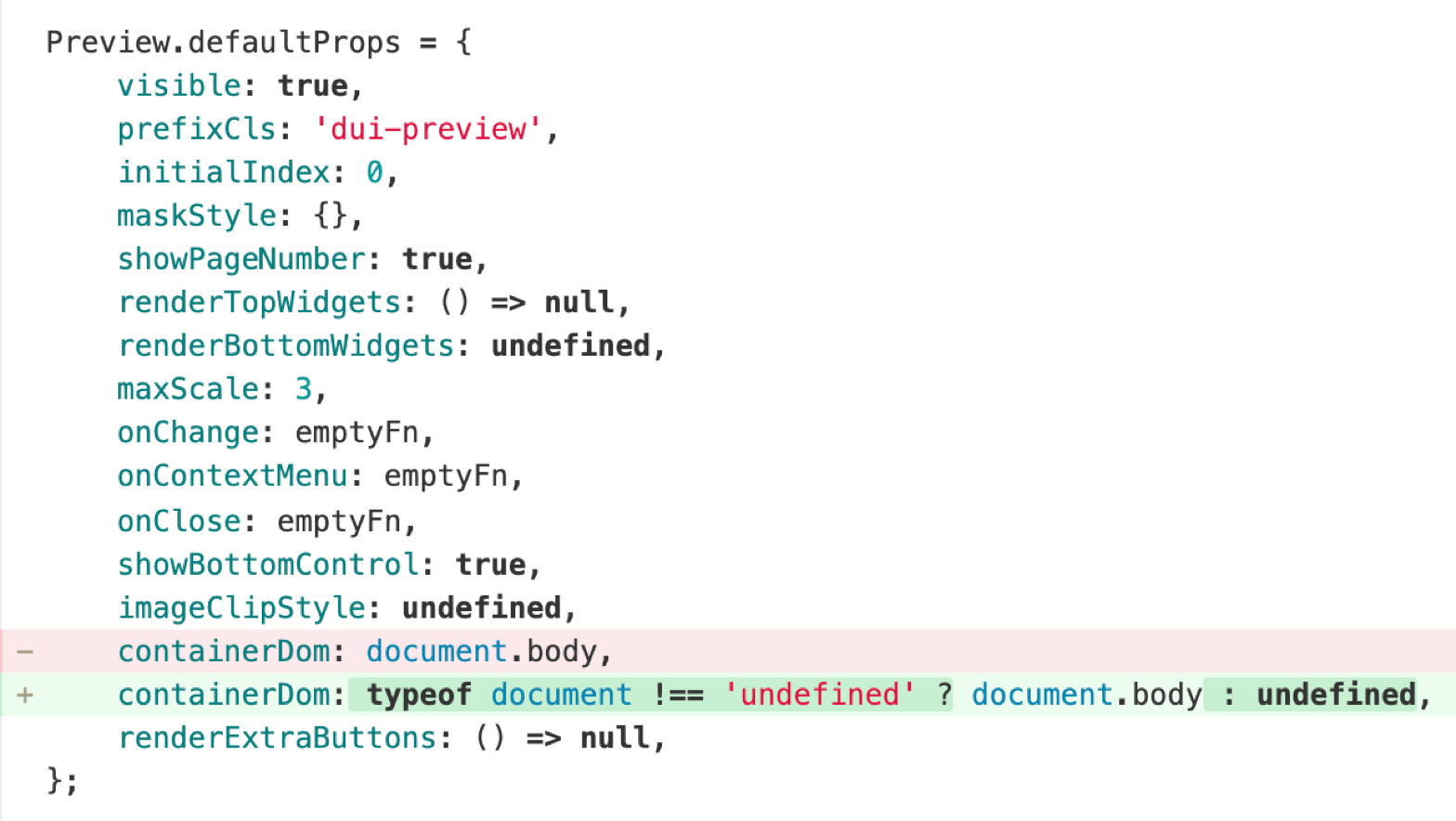
对于必需的依赖但是又不支持 Node 环境的,也只能是推动兼容一下。整个过程来说只有遇到两个内部模块是不支持的,兼容工作很小。对于社区成熟的库,很多都是支持 Node 下环境的。
比如组件库里默认的挂载点,在默认导出里使用 document.body ,只要多一下判断就可以了。
3.4 不支持的方法
举一些不支持方法的案例:
像这种在组件渲染完成后注册可见性事件的,明显在服务端是不需要的,直接屏蔽就可以了。
export const registerOnceVisibilityChange = () => {
if (__SERVER__) {
return;
}
if (onVisibilityChange) {
removeVisibilityChange(onVisibilityChange);
}
};useLayoutEffect 在服务端不支持,也应该屏蔽。但是需要看一下是否需要会有影响的逻辑。比如有个组件是 Slide,它的功能就像是页签,在子组件挂载后,切换子组件的显示。在服务端上明显是没有 DOM 挂载后的回调的,因此在服务端就需要改成直接渲染要显示的子组件就可以了。
export default function TransitionView({ visible = false, ...props }: TransitionViewProps) {
if (!__SERVER__) {
useLayoutEffect(() => {
}, [visible, props.duration]);
useLayoutEffect(() => {
}, [_visible]);
}
}useMemo 方法在服务端也不支持。
export function useStore(initialState?: RootStore) {
if (__SERVER__) {
return initializeStore(initialState);
}
return useMemo(() => initializeStore(initialState), [initialState]);
}总的来说使用屏蔽的方法,加上注入的有限的全局变量,其实屏蔽的逻辑不多。对于引入 jsdom 来说,结果可控,工作量又小。
3.5 基础组件库 DUI
对于要直出一个 React 应用,基础组件库的支持是至关重要的。腾讯文档里使用自己开发的 DUI 组件库,因为之前没有 SSR 的需求,所以虽然代码里有一些支持 Node 环境的逻辑,但是还不完善。
3.5.1 后渲染组件
有一些组件需要在鼠标动作或者函数式调用才渲染的,比如 Tooltip,Dropdown,Menu,Modal 组件等。在特定动作后才渲染子组件。在服务端上,并不会触发这些动作,就可以用空组件代替。(理想情况当然是组件里原生支持 Node 环境,但是有五六个组件需要支持,就先在业务里去兼容,也算给组件库提供个思路)
以 Tooltip 为例,这样可以支持组件同时运行在服务端和客户端,这里还补充了 className,是因为发现这个组件的根节点设置的样式会影响子组件的显示,因此加上。
import { Tooltip as BrowserTooltip } from '@tencent/dui/lib/components/Tooltip';
import { ITooltipProps } from './interface';
function ServerTooltip(props: ITooltipProps) {
// 目前知道这个 tooltip 的样式会影响,因此加上 dui 的样式
return (
<div className="dui-trigger dui-tooltip dui-tooltip-wrapper">
{props.children}
</div>
);
}
const Tooltip = __SERVER__ ? ServerTooltip : BrowserTooltip;
export default Tooltip;3.5.2 动态插入样式
DUI 组件会在第一次运行的时候会将对应组件的样式使用 <style> 标签动态插入。但是当我们在服务端渲染,是没有节点让它插入样式的。因此是在 vm 里提供了一些全局方法,供运行代码可以在文档的指定位置插入内容。需要注意的是我们首屏可能只用到了几个组件,但是如果把所有的组件样式都插到文档里,文档将会变大不少,因此还需要过滤一下。
if (isBrowser) {
const styleElement = document.createElement('style');
styleElement.setAttribute('type', 'text/css');
styleElement.setAttribute('data-dui-key', key);
styleElement.innerText = css;
document.head.appendChild(styleElement);
} else if (typeof injectContentBeforeRoot === 'function') {
const styleElement = `<style type="text/css" data-dui-key="${key}">${css}</style>`;
injectContentBeforeRoot(styleElement);
}同时组件用来在全局环境下管理版本号的方法,也需要抹平浏览器端和 Node 端的差异(这里其实还可以实现将 window.__dui_style_registry__ 注入到文档里,客户端从全局变量取出,实现复用)。
class StyleRegistryManage {
nodeRegistry: Record<string, string[]> = {};
constructor() {
if (isBrowser && !window.__dui_style_registry__) {
window.__dui_style_registry__ = {};
}
}
// 这里才是重点,在不同的端存储的地方不一样
public get registry() {
if (isBrowser) {
return window.__dui_style_registry__;
} else {
return this.nodeRegistry;
}
}
public get length() {
return Object.keys(this.registry).length;
}
public set(key: string, bundledsBy: string[]) {
this.registry[key] = bundledsBy;
}
public get(key: string) {
return this.registry[key];
}
public add(key: string, bundledBy: string) {
if (!this.registry[key]) {
this.registry[key] = [];
}
this.registry[key].push(bundledBy);
}
}3.6 公用组件库 UserAgent
腾讯文档里封装了公用的判断代码运行环境的组件库 UserAgent。虽然自执行的模块在架构设计上会带来混乱,因为很有可能随着调用地方的增多,你完全不知道模块在什么样的时机被以什么样的值初始化。对于 SSR 来说就很怕这种自执行的逻辑,因为如果模块里有不支持 Node 环境的代码,意味着你要么得改模块,要么不用,而不能只是屏蔽初始化。
但是这个库仍然得支持自执行,因为这个被引用得如此广泛,而且假设你要 ua.isMobile 这样使用,难道得每个文件内都 const ua = new UserAgent() 吗?这个库原来读取了 window.navigator.userAgent,为了里面的函数仍然能准确地判断运行环境,在 vm 虚拟机里通过读取 HTTP 头,提供了 global.navigator.userAgent ,在模块内兼容了这种情况。
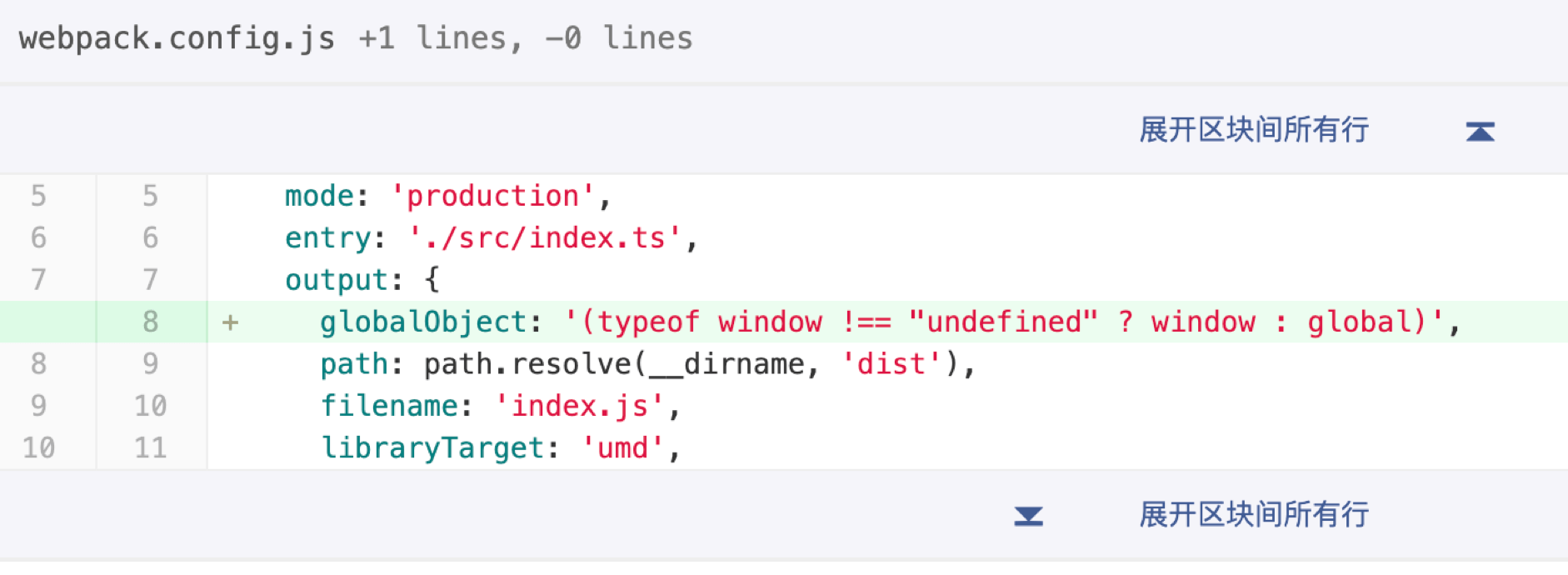

3.7 客户端存储
有个场景是列表头有个筛选器,当用户筛选了后,会将筛选选项存在 localStorage,刷新页面后,仍然保留筛选项。对于这个场景,在服务端直出的页面当然也是需要筛选项这个信息的,否则就会出现直出的页面已经呈现给用户后。但是我们在服务端如何知道 localStorage 的值呢?换个方式想,如果我们在设置 localStorage 的时候,同步设置 localStorage 和 cookie,服务端从 cookie 取值是否就可以了。
class ServerStorage {
getItem(key: string) {
if (__SERVER__) {
return getCookie(key);
}
return localStorage.getItem(key);
}
setItem(key: string, value: string) {
if (__SERVER__) {
return;
}
localStorage.setItem(key, value);
setCookie(key, value, 365);
}
}还有个场景是基于文件夹来存储的,即用户当前处于哪个文件夹下,就存储当前文件夹下的筛选器。如果像客户端一样每个文件夹都存的话,势必会在 cookie 里制造很多不必要的信息。为什么说不必要?因为其实服务端只关心上一次文件夹的筛选器,而不关心其他文件夹的,因为它只需要直出上次文件夹的内容就可以了。因此这种逻辑我们就可以特殊处理,用同一个 key 来存储上次文件夹的信息。在切换文件夹的时候,设置当前文件夹的筛选器到 cookie 里。
3.8 虚拟列表
3.8.1 react-virtualized
腾讯文档列表页为了提高滚动性能,使用 react-virtualized 组件。而且为了支持动态高度,还使用了 AutoSizer, CellMeasurer 等组件。这些组件需要浏览器宽高等信息来动态计算列表项的高度。但是在服务端上,我们是无法知道浏览器的宽高的,导致渲染的列表高度是 0。
3.8.2 Client Hints
虽然有项新技术 Client Hints 可以让服务端知道屏幕宽度,视口宽度和设备像素比 (DPR),但是浏览器的支持度并不好。
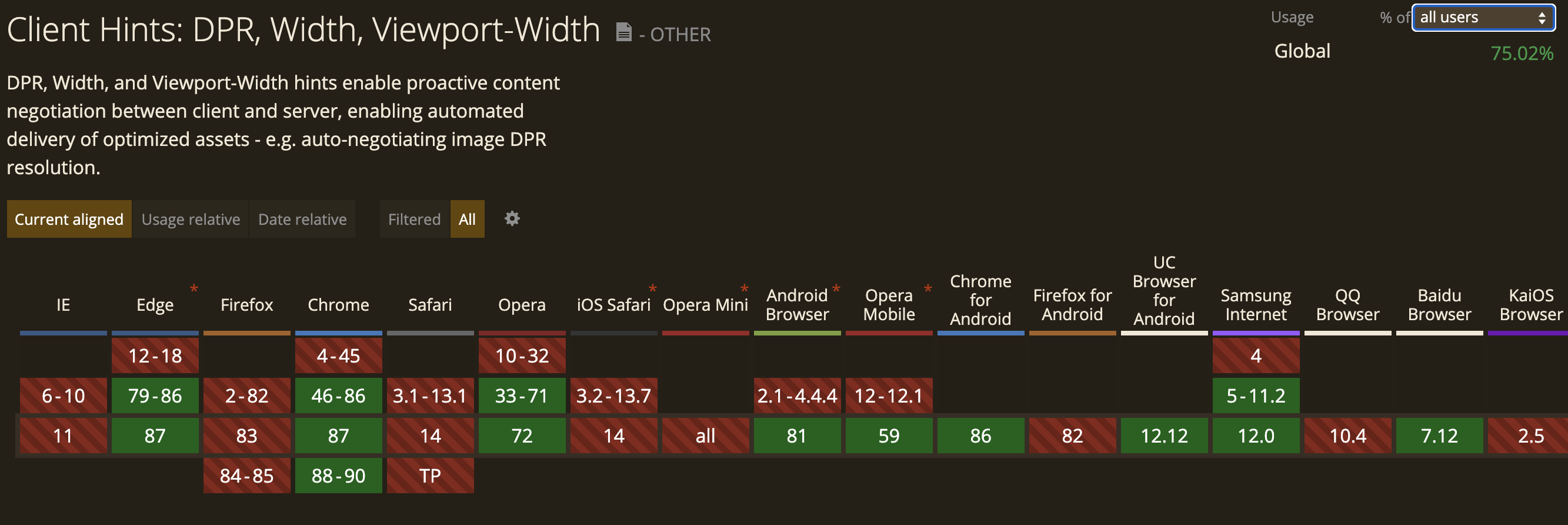
即使有 polyfill,用 JS 读取这些信息,存在 cookie 里。但是我们想如果用户第一次访问呢?势必会没有这些信息。再者即使是移动端宽高固定的情况,如果是旋转屏幕呢?更不用说 PC 端可以随意调节浏览器宽高了。因此这完全不是完美的解决方案。
3.8.3 使用 CSS 自适应
如果我们将虚拟列表渲染的项单独渲染而不通过虚拟列表,用 CSS 自适应宽高呢?反正首屏直出的情况下是没有交互能力的,也就没有滚动加载列表的情况。甚至因为首屏不可滚动,我们在移动端还可以减少首屏列表项的数目以此来减少 CGI 数据。
function VirtualListServer<T>(props: VirtualListProps<T>) {
return (
<div className="pc-virtual-list">
{
props.list.map((item, index) => (props.itemRenderer && props.itemRenderer(props.list[index], index)))
}
{!props.bottomText
? null
: <div className="pc-virtual-list-loading" style={{ height: 60 }}>
{props.bottomText}
</div>
}
</div>
);
}
const VirtualList = __SERVER__ ? VirtualListServer : VirtualListClient;3.9 不可序列化对象
本来这个小章节算是原 CSR 代码里实现的问题,但是涉及的逻辑较多,因此也只是在运用数据前来做转换。
前面说过我们会往文档里以全局变量的方式注入 state,怎么注入?其实就是用 JSON.stringify 将 state 序列化成字符串,如果这时候 state 里包含了函数呢?那么函数就会丢失。(不过看到下一小章节你会发现 serialize-javascript 是有保留函数的选项的,只是我觉得 state 应该是纯数据,正确的做法应该是将函数从 state 里移除,两种方式自由取舍吧)
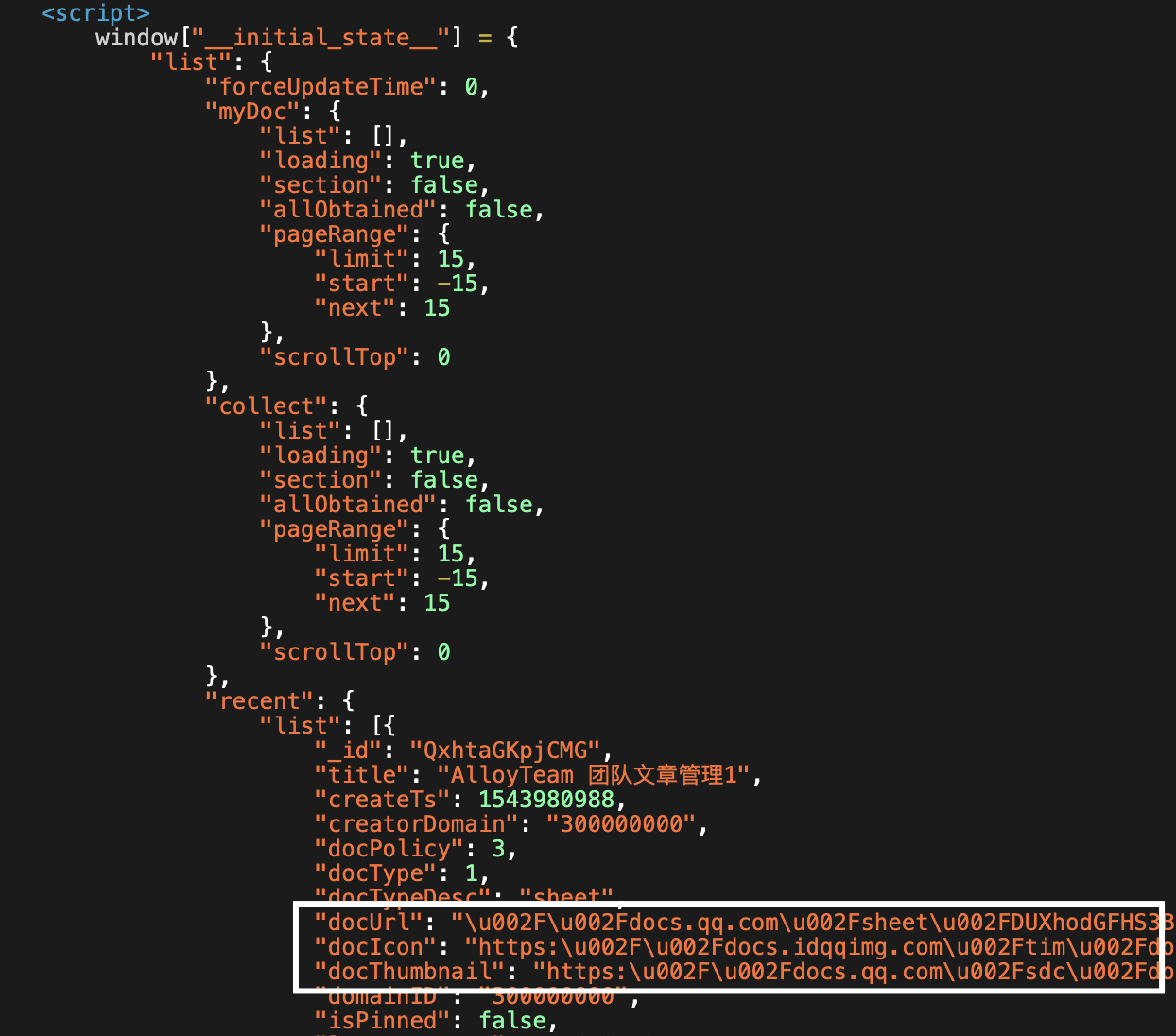
例如这里的 pageRange,里面包含了 add,getNext 等方法,在数据注入到客户端后,就只剩下纯数据:
const getDefaultList = () => ({
list: [],
loading: true,
section: false,
allObtained: false,
pageRange: new PageRange({ start: -listLimit, limit: listLimit }),
scrollTop: 0,
});在客户端使用的时候,还需要将 pageRange 转成新的实例:
export function pageRangeTransform(opt: PageRange) {
if (typeof opt.add === 'function') {
return opt;
}
return new PageRange(opt);
}3.10 引用类型的 state
还遇到一个比较有趣的问题如下图:
- db 是一个内存上的数据对象,用来存储列表等相关的数据的,而 state 里的列表其实只是 db 里的一个引用;
- 在更新列表数据的时候,发送了 CGI,其实是更新了 db 里的列表数据;
- 在更新列表项是否可编辑的数据的时候,其实也是更改的 db 里的数据,然后通过一个 forceTime 来强制 state 更新视图;
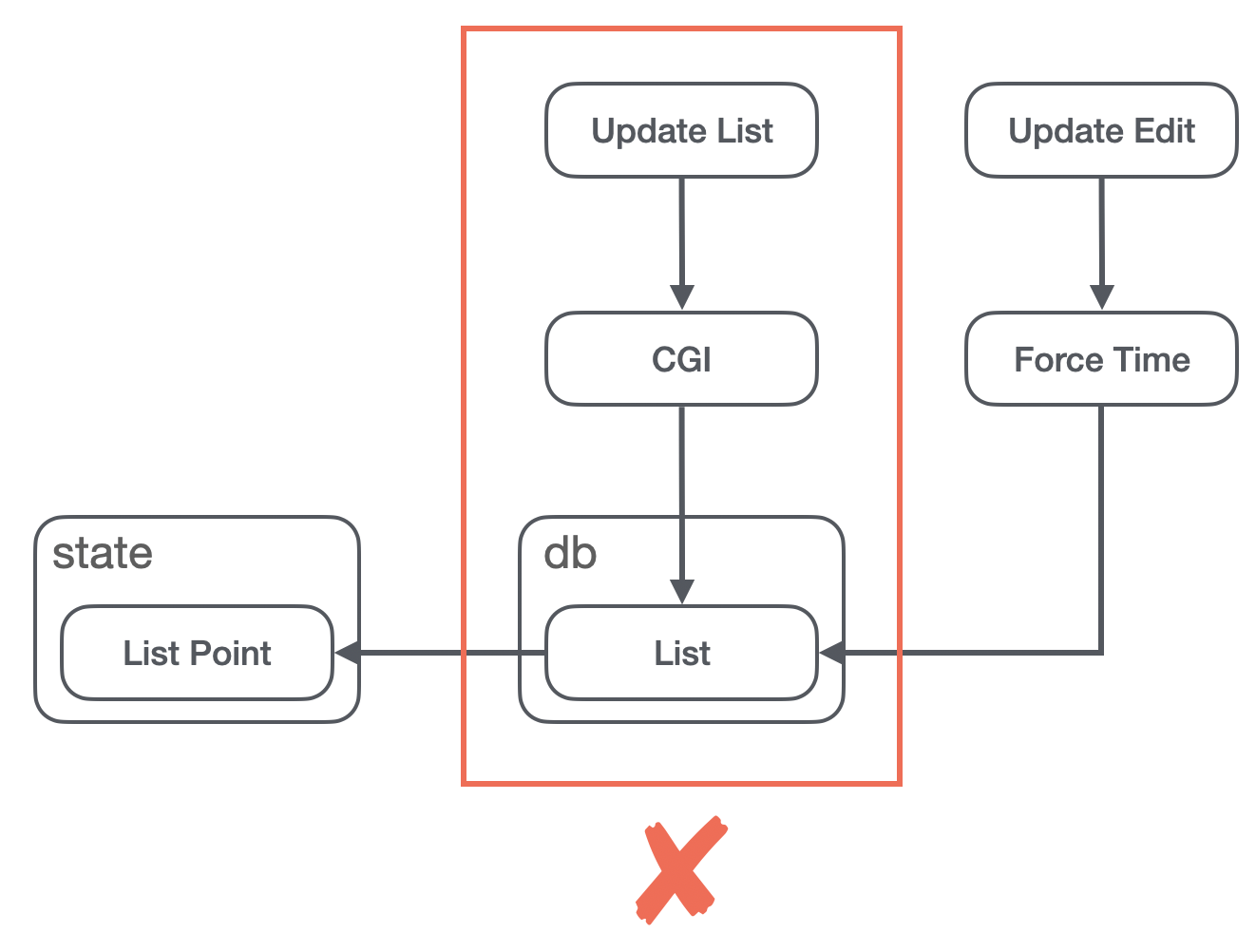
这对于加入了 SSR 的 CSR 来说会有几点问题:
- 因为我们复用了服务端注入的数据,省去了 CGI 的步骤,在客户端上也就没有往 db 里添加列表数据;
- state 里的列表数据不再是引用的 db 里的数据,因此更新 forceTime,是强制不了 state 更新视图的;
两个典型的 Bug(代码里写了注释,应该不用再解释了):
/*
* 如果有 preloadState,需要调用 db 来设置一下数据。有一个问题是:
* 1. CSR 列表的 0-30 的数据是通过 API 拉取的,在 API 里通过 db 设置了 0-30 的数据
* 2. SSR 0-30 的数据是通过 preloadedState 注入到客户端的,没有通过 db 设置 0-30 的数据
* 3. 列表往下拉的时候,通过 CGI 拉取 30-60 的数据,这时候通过 db 合并,会丢失 0-30 的数据
*/
if (preloadedState) {
const db = getDBSingleton();
if (preloadedState.list && preloadedState.list.recent) {
const transedList = transformForInitialState(preloadedState.list.recent.list);
preloadedState.list.recent.list = db.register(ListTypeInStore.recent, transedList);
}
}if (preloadedState.folderUI && preloadedState.folderUI.viewStack.length) {
const folderData = preloadedState.folderUI.viewStack[0];
const { folderID, list } = folderData;
if (list && list.length) {
/*
* 为什么要用 db.register 返回的 list 重新赋值?因为客户端上的 state 引用的是 db 里的数据,在调用
* forceUpdate 的时候只是更新了个时间,如果这里不保持一致,在调用 forceUpdate 的时候就不会更新了。
* 典型的 Bug,按了右键重命名无效
*/
folderData.list = registerDBForInitialState(folderID, transformForInitialState(list));
}
}3.11 安全
使用字符串拼接的方式插入初始化的 state,需要转义而避免 xss 攻击。我们可以使用 serialize-javascript 库来转义数据。
import serialize from 'serialize-javascript';
export function injectDataToClient(key: string, data: any) {
const serializedData = serialize(data, {
isJSON: true,
ignoreFunction: true,
});
return `<script>window["${key}"] = ${serializedData}</script>`;
}
export function getStateScriptTag(initialState: any) {
return injectDataToClient('__initial_state__', initialState);
};
3.12 服务端路由
对于单页面来说,使用 react-router 来管理路由,服务端也需要直出相对于的组件。需要做的只是将路由组件换成 StaticRouter ,通过 localtion 提供页面地址和 context 存储上下文 。
import { StaticRouter as Router } from 'react-router-dom';
(async () => {
const routerContext = {};
const bodyHtml = ReactDOMServer.renderToString(
<Router basename={'/desktop'} location={TSRENV.href} context={routerContext} >
<Provider store={store}>
<ServerIndex />
</Provider>
</Router>
);
})();
4. 运行环境
4.1 网络
4.1.1 网络请求
当浏览器发起 CGI 请求,形如 https://docs.qq.com/cgi-bin/xxx,不仅需要解析 DNS,还需要建立 HTTPS 链接,还要再经过公司的统一网关接入层。如果我们的 SSR 服务同部署在腾讯云上,是否有请求出去绕一圈再绕回来的感觉?因为我们的服务都接入了 L5(服务发现和负载均衡),那么我们可以通过解析 L5 获得 IP 和端口,以 HTTP 发起请求。
以兼容 L5 的北极星 SDK 来解析(cl5 需要依赖环境,在我使用的基础镜像 tlinux-mini 上会有错误)。
PS: Axios 发送 HTTPS 请求会报错,因此在 Node 端换成了 Got,方便本地开发。
const { Consumer } = require('@tencent/polaris');
const consumer = new Consumer();
async function resolve(namespace, service) {
const response = await consumer.select(namespace, service);
if (response) {
const {
instance: { host, port },
} = response;
return `${host}:${port}`;
}
return null;
}需要注意的是,北极星的第一次解析比较耗时,大概 200ms 的样子,因此应该在应用启动的时候就调用解析一次,后续再解析就会是 1~3ms 了。
这里还有个点是我们应该请求哪个 L5?假设有两个 CGI,doclist 和 userInfo,我们是解析它们各自的 L5,通过 OIDB 的协议请求吗?考虑三个方面:
- 这里询问了文档后台,通过 OIDB 并没有比通过 HTTP 协议快多少;
- 我们需要一直维护 CGI 和 L5 的对应关系,如果后台重构,信息同步不到位,换了新的 L5,服务将会挂掉;
- 没有更新 xsrf 的逻辑;
好在文档还有个统一的接入层 tsw,因此我们其实只需要解析接入层 tsw 的 L5,将请求都发往它就可以了。
4.1.2 cookie
在 SSR 代发起 CGI 请求,不仅需要从请求取出客户端传递过来的 cookie 来使用,在我们的 tsw 服务上,还会验证 csrf,因此 SSR 发出 CGI 请求后,可能 tsw 会更新 csrf,因此还需要将 CGI 请求返回的 set-cookie 再设置回客户端。
const setCookie = require('set-cookie-parser');
function setCookies(cookis) {
const parsedCookies = setCookie.parse(cookis || []) || [];
if (ctx.headerSent) {
return;
}
parsedCookies.map((cookieInfo) => {
const { name, value, path, domain, expires, secure, httpOnly, sameSite } = cookieInfo;
try {
ctx.cookies.set(name, value, {
overwrite: true,
path,
domain,
expires,
secure,
httpOnly,
sameSite,
});
} catch (err) {
logger.error(err);
}
});
}overwrite 设置为 true 是因为当我们有多个 CGI 请求,所返回的同名 set-cookie 如果不覆盖的话,会使得 SSR 返回的 HTTP 头很大。
还要说说 secure 参数。这个参数表示 cookie 是否只能是 HTTPS 下传输。我们的应用是在 tsw 服务之后的,一般来讲也都会在 nginx 之后以 http 提供服务。那么我们就设置不了这个 secure 参数。如果要设置的话,需要有两步:
-
初始化 koa 的时候,设置 proxy;
const app = new Koa({ proxy: true }) -
koa 前面的代理设置
X-Forwarded-Proto头部,表明是工作在 HTTPS 模式下;
但是实际上在我的服务里没有收到这个头部,因此仍然会报错,由于我们没法去改 tsw,也很清楚地知道我们是工作在代理之后,有个解决方案:
this.app.use(async (ctx, next) => {
ctx.cookies.secure = true;
await next();
});4.2 并发和上下文隔离
我们来考虑这样一种情况:
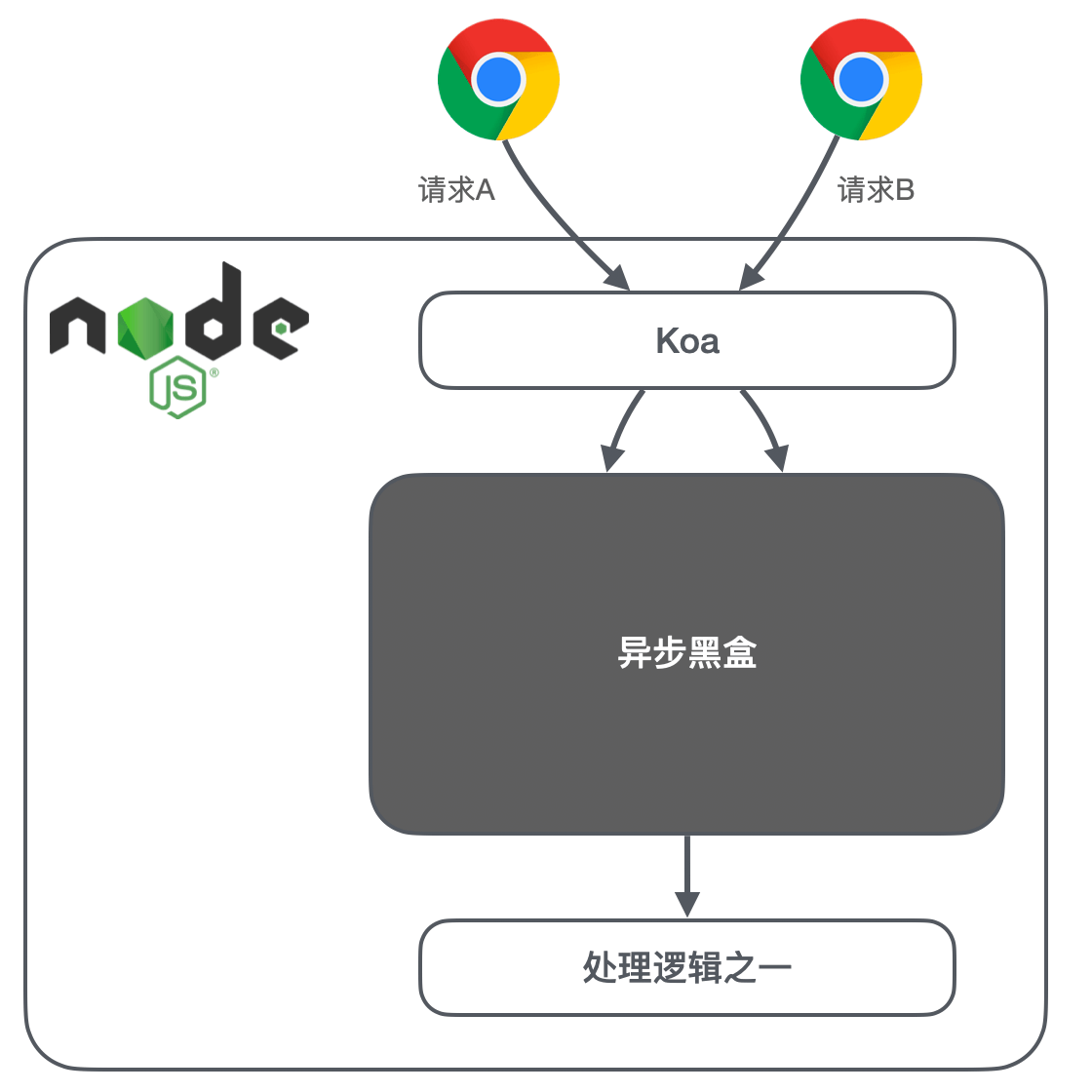
当有两个请求 A 和 B 一前一后到达 Server,在经过一大串的异步逻辑之后。到达后面的那个处理逻辑的时候,它怎么知道它在处理哪个请求?方法当然是有:
- 把 koa 的
ctx一层一层传递,只要有涉及到具体请求的函数,都传递一下ctx(是不是疯狂?); - 或者把 ctx 存在 state 里,需要
ctx的话从 state 里取(先不说这违反了 state 里应该放纯数据的原则,如果是一些工具函数呢?比如getCookie这样的函数,让它的 cookie 从哪里取?想想是不是头大?);
因此我们需要想个办法,将 A 和 B 的请求隔离开来。
4.2.1 cluster 和 worker
如果说要隔离请求,我们可以有 cluster 模块提供进程粒度的隔离,也可以通过 worker_threads 模块提供线程粒度的隔离。但是难道我们一个进程和一个线程同时只能处理一个请求,只有一个请求完全返回结果后才能处理下一个吗?这显然是不可能的。
但是为了下面的错误捕获问题,我确实用 worker_threads + vm 尝试了好几种方法,虽然最后都放弃了。并且因为使用 worker_threads 可以共享线程数据的优点在这个场景下并没有多大的应用场景,反而是 cluster 可以共享 TCP 端口,最后是用 cluster + vm ,不过这是后话了。
4.2.2 domain
上下文隔离的技术,从 QQ 空间团队 tsw 那里学了个比较骚的方法,主要有两个关键点:
- process.domain 总是指向当前异步流程的上下文,因此可以将需要的数据挂载到 process.domian 上;
- 用
Object.defineProperty设置数据的 getter 和 setter 函数,保证操作到的是 process.domain 上的对应数据;
用简短的代码演示就是这样的:
const domain = require('domain');
Object.defineProperty(global, 'myVar', {
get: () => process.domain.myVar,
set: (value) => {
process.domain.myVar = value;
},
});
const handler = (label) => {
setTimeout(() => {
console.log(`${label}: ${global.myVar}`);
}, (1 + Math.random() * 4) * 1000);
};
for (let i = 0; i < 3; i++) {
const d = domain.create();
d.run(() => {
global.myVar = i;
handler(`test-${i}`);
});
}
// test-1: 1
// test-0: 0
// test-2: 2但是这个方案存在什么样的问题?
- domain 没法保证虽然对象在它 run 函数里初始化,process.domain 一定有值,也可能是
undefined; - requre 过的文件,被 cache 了,需要执行清除缓存的操作,重新 require。虽然可以用 defineProperty 来定义值,但是如果有的模块是
const moduleVar = global.myVar; module.exports = moduleVar;没有重新执行的话,导出的值将是错误的;
4.3 vm
上下文隔离,我们还可以用 vm 来做。(然后我们的挑战就变成了怎么把十几万行的代码放在 vm 里跑,为什么需要把十几万行代码都放进去?因为后面会说到被 require 的模块里访问 global 的问题,虽然后面的后面解决了这个问题)
vm 的一个基本使用姿势是这样的:
const vm = require('vm');
const code = 'console.log(myVar)';
vm.runInNewContext(code, {
myVar: 'AlloyTeam',
console,
});
// AlloyTeam功能是不是很像 eval?,使用 eval 的话:
let num = 1;
eval('num ++');
console.log(num);
// 2使用 Function 的话:
/**
* @file function.js
*/
global.num = 1;
(new Function('step', 'num += step'))(1);
console.log(num);
// node function.js
// >2细心的读者可能会发现,Function 的例子里,我写的是 global.num = 1 而不是 let num = 1,这是为什么?
- 由
Function构造器创建的函数不会创建当前环境的闭包,而是被创建在全局环境里; - 我这里的代码写在
function.js文件里,是当做一个模块被运行的,是在模块的作用域里; - 基于以上 2 点,
Function里的代码能访问到的变量就是global和它的局部变量step,如果写成let num = 1将会报错;
使用 evel 和 Function 可以做到吗?感觉理论上像是可以的,假设我们给每个请求分配 ID,使用 Object.defineProperty 来定义数据的存取。但是我没有试过,而是使用成熟的 vm 模块,好奇的读者可以试一下。
另外因为我们并没有运行外部的代码,要在 vm 里跑的都是业务代码,因此不关心 vm 的进程逃逸问题,如果有这方面担忧的可以用 vm2。
4.3.1 global
我们在 Node 环境下访问全局变量,有两种方式:
(() => {
a = 1;
global.b = 2;
})();
console.log(a);
console.log(b);
// 1
// 2而在 vm 里,是没有 global 的,考察以下代码:
const vm = require('vm');
global.a = 1;
const code = `
console.log(typeof global);
console.log(typeof a);
`;
vm.runInNewContext(code, {
console,
});
// undefined
// undefined因此假设我们要支持代码里能够以 global.myVar 和 myVar 两种方式来访问上下文里的全局变量的话,就要构造出一个 global 变量。
上下文的全局变量默认是空的,不仅 global 没有,还有一些函数也没有,我们来看看最终构造出的上下文是都有什么:
async getVMContext(renderJSFile) {
const pathInfo = path.parse(renderJSFile);
// 模块系统的变量
const moduleGlobal = {
__filename: renderJSFile,
__dirname: pathInfo.dir,
};
const commonContext = {
Buffer,
process,
console,
require,
exports,
module,
};
/* 业务上定义的的全局对象,运行的时候会重新赋值
* {
* window: undefined,
* navigator: {
* userAgent: '',
* },
* location: {
* search: '',
* },
* }
*/
const browserGlobal = renderConfig.vmGlobal(renderJSFile);
return vm.createContext({
...commonContext,
...moduleGlobal,
...global,
...browserGlobal,
// 重写 global 循环变量
global: {
...browserGlobal,
},
});
}4.3.2 require
前面说到 vm 的上下文默认是空的,然后我们给它传递了 module,exports,require,那么它能 require 外部模块了,但是被 require 的模块如果访问 global,会是 vm 里我们创建的 global,还是宿主环境下的 global 呢?
我们有个文件 vm-global-required.js 是要被 require 的:
const myVar = global.myVar;
console.log('[required-file]:', myVar);我们还有个文件是宿主环境:
const vm = require('vm');
global.myVar = 1;
const code = `
console.log("[vm-host]:", global.myVar);
require('./vm-global-required');
`;
vm.runInNewContext(code, {
global: {
myVar: 2,
},
console,
require,
});运行代码,结果是:
// [vm-host]: 2
// [required-file]: 1可以看到被 require 的模块所访问的 global 并不是 vm 定义的上下文,而是宿主环境的 global。
4.3.3 代码编译缓存
以 vm 创建的代码沙箱是需要编译的,我们不可能每个请求过来都重复编译,因此可以在启动的时候就提前编译缓存:
compilerVMByFile(renderJSFile) {
const scriptContent = fileManage.getJSContent(renderJSFile);
if (!scriptContent) {
return;
}
const scriptInstance = new vm.Script(scriptContent, {
filename: renderJSFile,
});
return scriptInstance;
}
getVMInstance(renderJSFile) {
if (!this.vmInstanceCache[renderJSFile]) {
const vmInstance = this.compilerVMByFile(renderJSFile);
this.vmInstanceCache[renderJSFile] = vmInstance;
}
return this.vmInstanceCache[renderJSFile];
}但是其实 v8 编译是不编译函数体的,好在可以设置一下:
const v8 = require('v8');
v8.setFlagsFromString('--no-lazy');(编译部分还尝试过 createCachedData,可以详见以下错误捕获的使用 filename 章节)
4.3.4 超时
vm 运行的时候可以设置 timeout 参数控制超时,当超过时间后会报错:
const vm = require('vm');
const vmFunc = new vm.Script(`
while(1) {}
`);
try {
vmFunc.runInNewContext({
http,
console,
}, {
timeout: 100,
})
} catch (err) {
console.log('vm-timeout');
}
// vm-timeout但是它的超时真的有效吗?我们来做个试验。如以下代码:
- 设置了
timeout是 100; - 用 process 监听了错误,如果超时触发了错误,process 就会捕获到错误输出出来;
/timeout-get在 2000ms 后才返回结果;
const Koa = require('koa');
const Router = require('koa-router');
const vm = require('vm');
const http = require('http');
const app = new Koa();
const router = new Router();
router.get('/timeout-get', async (ctx) => {
await new Promise((resolve) => {
setTimeout(() => {
ctx.body = 'OK';
resolve();
}, 2000);
});
});
app.use(router.routes()).use(router.allowedMethods());
app.listen(3000);
process.on('unhandledRejection', (err) => {
console.log('unhandledRejection', err);
});
process.on('uncaughtException', (err) => {
console.log('uncaughtException', err);
});
console.time('http-cost');
const vmFunc = new vm.Script(`
http.get('http://127.0.0.1:3000/timeout-get', (res) => {
const { statusCode } = res;
console.log('statusCode:', statusCode);
console.timeEnd('http-cost');
process.exit(0);
})`
);
vmFunc.runInNewContext({
http,
console,
process,
}, {
timeout: 100,
microtaskMode: 'afterEvaluate',
})
console.log('vm-executed');
输出结果是什么呢?
vm-executed
statusCode: 200
http-cost: 2016.098ms说明 vm 的这个 timeout 参数在我们的场景下是不一定有效的,因此我们还需要在宿主环境额外设置超时返回。
4.4 错误捕获
我们的 SSR 和普通的后台服务最大的区别在于什么?我想是在于我们不允许返回空内容。后台的 CGI 服务在错误的时候,返回个错误码,有前端来以更友好的方式展示错误信息。但是 SSR 的服务,即使错误了,也需要返回内容给用户,否则就是白屏。因此错误的捕获显得尤为重要。
总结一下背景的话:
- vm 所执行的代码可能来自于第三方,但是整个项目是提供基础镜像,第三方基于镜像自行部署的,因此不关心 vm 里的代码安全问题,不用用到 vm2
- vm 里的代码是有可能出错的,错误可能来自于同步代码、异步代码或者未处理的 Promise 错误
- vm 代码是异步并行的,假设每次执行 vm 代码都有一个 id
- vm 里的代码即使出错,也必须要知道是哪个 id 的 vm 代码执行出错了,来执行兜底的策略
4.4.1 process 捕获
在 node 里,如果要捕获未知的错误,我们当然可以用 process 来捕获
process.on('unhandledRejection', (err) => {
// do something
});
process.on('uncaughtException', (err) => {
// do something
});这代码不仅可以捕获同步、异步错误,也能捕获 Promise 错误。但同时,我们从 err 对象上也获取不了出错时候的上下文信息。像背景里的要求,就不知道是哪个 id 的 vm 出错了
4.4.2 try...catch
如果以 vm 来执行代码的话,我们大可以在代码的外部包裹 try...catch 来捕获异常。看下面的例子,try...catch 捕获到了错误,错误就没再冒泡到 process。
const vm = require('vm');
process.on('uncaughtException', (err) => {
console.log('[uncaughtException]:', err);
});
const script = new vm.Script(`
try {
throw new Error('from vm')
} catch (err) {
console.log(err)
}
`);
script.runInNewContext({ Error, console });
// Error: from vm
// at evalmachine.<anonymous>:3:154.4.3 异步错误
改写上面的例子,将错误在异步函数里抛出,try...catch 捕获不到错误,错误冒泡到 process,被 uncaughtException 事件捕获到
const vm = require('vm');
process.on('uncaughtException', (err) => {
console.log('[uncaughtException]:', err);
});
process.on('unhandledRejection', (err) => {
console.log('[unhandledRejection]:', err);
});
const script = new vm.Script(`
try {
setTimeout(() => {
throw new Error('from vm')
})
} catch (err) {
console.log(err)
}
`);
script.runInNewContext({ Error, console, setTimeout });
// [uncaughtException]: Error: from vm
// at Timeout._onTimeout (evalmachine.<anonymous>:4:19)
那有什么办法捕获异步错误吗?办法还是有的,node 里有个 domain 模块,可以用来捕获异步错误。(虽然已经标记为废弃状态,但是已经用 async_hooks 重写了,意味着即使真的被废弃,也能自己实现一个)
继续改写上面的例子,将 vm 放在 domain 里执行,可以看到错误被 domain 捕获到了
const vm = require('vm');
const domain = require('domain');
process.on('uncaughtException', (err) => {
console.log('[uncaughtException]:', err);
});
process.on('unhandledRejection', (err) => {
console.log('[unhandledRejection]:', err);
});
const script = new vm.Script(`
try {
setTimeout(() => {
throw new Error('from vm')
})
} catch (err) {
console.log(err)
}
`);
const d = domain.create();
d.on('error', (err) => {
console.log('[domain-error]:', err);
});
d.run(() => {
script.runInNewContext({ Error, console, setTimeout });
});
// [domain-error]: Error: from vm
// at Timeout._onTimeout (evalmachine.<anonymous>:4:19)
4.4.4 Promise 错误
但是假如将上一个例子的 vm 代码改成 Promise 执行呢?domain 捕获不到错误,错误冒泡到 process 上
const vm = require('vm');
const domain = require('domain');
process.on('uncaughtException', (err) => {
console.log('[uncaughtException]:', err);
});
process.on('unhandledRejection', (err) => {
console.log('[unhandledRejection]:', err);
});
const script = new vm.Script(`
Promise.resolve().then(() => {
throw new Error('notExistPromiseFunc')
})
`);
const d = domain.create();
d.on('error', (err) => {
console.log('[domain-error]:', err);
});
d.run(() => {
script.runInNewContext({ Error, console, setTimeout });
});
// [unhandledRejection]: Error: notExistPromiseFunc
// at evalmachine.<anonymous>:3:15
为什么?node 文档里是这么说的
Domains will not interfere with the error handling mechanisms for promises. In other words, no
'error'event will be emitted for unhandledPromiserejections.
那有什么办法吗?这里想了两个比较骚的写法。
4.4.4.1 使用 filename
我们知道 vm 在执行的时候,是可以提供一个 filename 属性,在错误的时候,会被添加到错误堆栈内。默认值是 'evalmachine.<anonymous>' 也就是我们上面的错误经常看到的第二行代码错误的位置。这就带来了操作的空间。
const vm = require('vm');
const markStart = '<vm-error>';
const markEnd = '</vm-error>';
const getContext = () =>
vm.createContext({
console,
process,
setTimeout,
});
const parseErrorStack = (err) => {
const errorStr = err.stack;
const valueStart = errorStr.indexOf(markStart);
const valueEnd = errorStr.lastIndexOf(markEnd);
if (valueStart !== -1 && valueEnd !== -1) {
return errorStr.slice(valueStart + markStart.length, valueEnd);
}
console.log('[parse-error]');
return null;
};
process.on('unhandledRejection', (err) => {
console.log('[unhandledRejection]:', parseErrorStack(err));
});
process.on('uncaughtException', (err) => {
console.log('[uncaughtException]:', parseErrorStack(err));
});
const getScript = (flag) => {
const filename = `${markStart}${flag}${markEnd}`;
return new vm.Script(
`
(() => {
new Promise((resolve, reject) => {
setTimeout(() => {
reject(new Error('${flag}'));
}, 100)
})
})()
`,
{ filename }
);
};
(async () => {
for (let i = 0; i < 3; i++) {
await getScript(i).runInContext(getContext());
}
})();
// [unhandledRejection]: 0
// [unhandledRejection]: 1
// [unhandledRejection]: 2看下上面的代码结构,我们做了几件事:
- 在 vm 代码编译的时候,以
vm-error标识符标记了我们要传递到错误堆栈的值 - 在 process 捕获 Promise 错误
- 在 process 捕获到 Promise 错误的时候,从错误堆栈上根据标识符解析出我们要的值
但是这样的代码存在什么问题?
最主要的问题在于 filename 是编译进去的,即使生成 v8 代码缓存的 Buffer,后面用这个 Buffer 来编译一个新的 script 实例,传递进新的 filename,仍然改变不了之前的值。所以会带来代码每次都需要编译的成本。
我们可以来实践以下:
const vm = require('vm');
require('v8').setFlagsFromString('--no-lazy');
const markStart = '<vm-error>';
const markEnd = '</vm-error>';
const getContext = myVar => vm.createContext({
console,
process,
setTimeout,
myVar,
});
const parseErrorStack = (err) => {
const errorStr = err.stack;
const valueStart = errorStr.indexOf(markStart);
const valueEnd = errorStr.lastIndexOf(markEnd);
if (valueStart !== -1 && valueEnd !== -1) {
return errorStr.slice(valueStart + markStart.length, valueEnd);
}
console.log('[parse-error]');
return null;
};
process.on('unhandledRejection', (err) => {
console.log('[unhandledRejection]:', parseErrorStack(err));
});
process.on('uncaughtException', (err) => {
console.log('[uncaughtException]:', parseErrorStack(err));
});
const getFileName = flag => `${markStart}${flag}${markEnd}`;
const code = `
(() => {
new Promise((resolve, reject) => {
setTimeout(() => {
reject(new Error(myVar));
}, 100)
})
})()
`;
const scriptCache = new vm.Script(code, {
filename: getFileName(-1),
});
const scriptCachedData = scriptCache.createCachedData();
const getScript = flag => new vm.Script(' '.repeat(code.length), {
filename: getFileName(flag),
cachedData: scriptCachedData,
});
(async () => {
for (let i = 0; i < 3; i++) {
await getScript(i).runInContext(getContext(i));
}
})();
看上面的代码,对比上一个例子,主要有这几个改动:
- 缓存了 vm 代码编译后的实例,filename 设置的 -1
- 循环内的 flag 标志是通过 myVar 注入到 vm 的全局变量,在 vm 里 throw 这个 flag 错误值的
- 循环内的 vm 执行,filename 设置的 0 - 3
结果:编译后的代码实例并不会因为使用 cachedData 重新编译后,filename 就会被改变,因此就无法使用 cacheData + filename 的方式来既要减少编译时间又想要自定义错误堆栈。
4.4.4.2 重写 Promise
当我们想同步和异步代码都能捕获得到,那么只剩下 Promise 错误了。什么情况会报 Promise 未处理的错误呢?也就是没有写 catch 的情况。那么如果我们改写 Promise ,将每个 Promise 都加上一个默认的 catch 函数,是否能达到期望呢?
const vm = require('vm');
let processFlag;
process.on('unhandledRejection', (err) => {
console.log('[unhandledRejection-processFlag]:', processFlag);
});
const getVMPromise = (flag) => {
const vmPromise = function (...args) {
const p = new Promise(...args);
p.then(
() => {},
(err) => {
processFlag = flag;
throw err;
}
);
return p;
};
['then', 'catch', 'finally', 'all', 'race', 'allSettled', 'any', 'resolve', 'reject', 'try'].map((key) => {
if (Promise[key]) {
vmPromise[key] = Promise[key];
}
});
return vmPromise;
};
const getContext = (flag) =>
vm.createContext({
Promise: getVMPromise(flag),
console,
setTimeout,
});
const getScript = (flag) => {
return new vm.Script(`
new Promise((resolve, reject) => {
setTimeout(() => {
console.log("[vm-current-task]:", "${flag}");
reject()
}, (1 + Math.random() * 4) * 1000);
})
`);
};
for (let i = 0; i < 3; i++) {
getScript(i).runInContext(getContext(i));
}
// [vm-current-task]: 0
// [unhandledRejection-processFlag]: 0
// [vm-current-task]: 2
// [unhandledRejection-processFlag]: 2
// [vm-current-task]: 1
// [unhandledRejection-processFlag]: 1考察以上的代码,我们做了这些事:
- 改写了 Promise,在 Promise 添加了第一个 then 方法来处理错误
- 在自定义的 Promise 的第一个 then 方法里存储了当前异步任务的上下文
- 将自定义的 Promise 当做全局变量传递给 vm
结果:在一个随机的任务 ID 上,成功在 process 上捕获到了上下文的信息。(但是 Promise 实现的精华在于 then 之后的链式调用,这在上面的代码是没有体现的。)
4.4.5 必要性思考
重写 Promise 的方案可行吗?看起来是可行的,但其实最后也没有用这个方案(其实是我还没实施。。。)。因为假设我一个 32 核的 Pod,fork 出 32 个进程处理请求,平均分到每个进程的请求同一时间也不会很多。而出错是应该在编码和系统测试就应该避免的,或者自动化测试,或者生成骨架屏时避免。如果要同时捕获这三个错误,需要在异步代码都使用 domain 捕获(可能会有性能问题)和 Promise 记录上下文。其实我们可以在出错的时候将当前进程所处理的所有请求直接返回原文档,回退到无 SSR 的状态。(不过 Promise 的方案仍然值得研究尝试一下,会发大篇幅也是因为之前陷进去了这个问题,研究了好一段时间)
4.5 重定向
登录态的问题和文档强相关,但是仍然想要抛出来和大家探讨一下重定向的这个问题。
腾讯文档的登录态在前端是无法完全判断的,只有两种最基本的情况前端是知道没有登录态:
- 没有 cookie;
- cookie 里没有 uid 和 uid_key;
如果是登录态过期,那么只能是在发起 CGI 请求,后台返回具体的错误码之后才知道。所以 CSR 的登录是在列表页显示,并且正常渲染的情况下,发现 CGI 有具体的登录态错误码了,就动态加载登录模块来提醒用户登录。整个的效果就是这样的:

4.5.1 rewrite
当我们引入了 SSR 后,发送 CGI 请求遇到特定的登录态错误码我们是知道的。那么我们为什么不直接返回登录页就可以了呢?很简单,直接 ctx.redirect 302 重定向到登录页就可以了,但是问题来了:
- 我们的 PC 端没有独立的登录页,是用动态加载模块的方式来在当前页面展示登录框的;
- 需要处理 URL 跳转的问题,不仅是从外部跳转过来的带有登录态的 URL,还要处理登陆完后的 URL 跳转问题;
- 登录的模块在其他的库,就需要去改到那个库发布才可以;
有没有更好的方法呢?
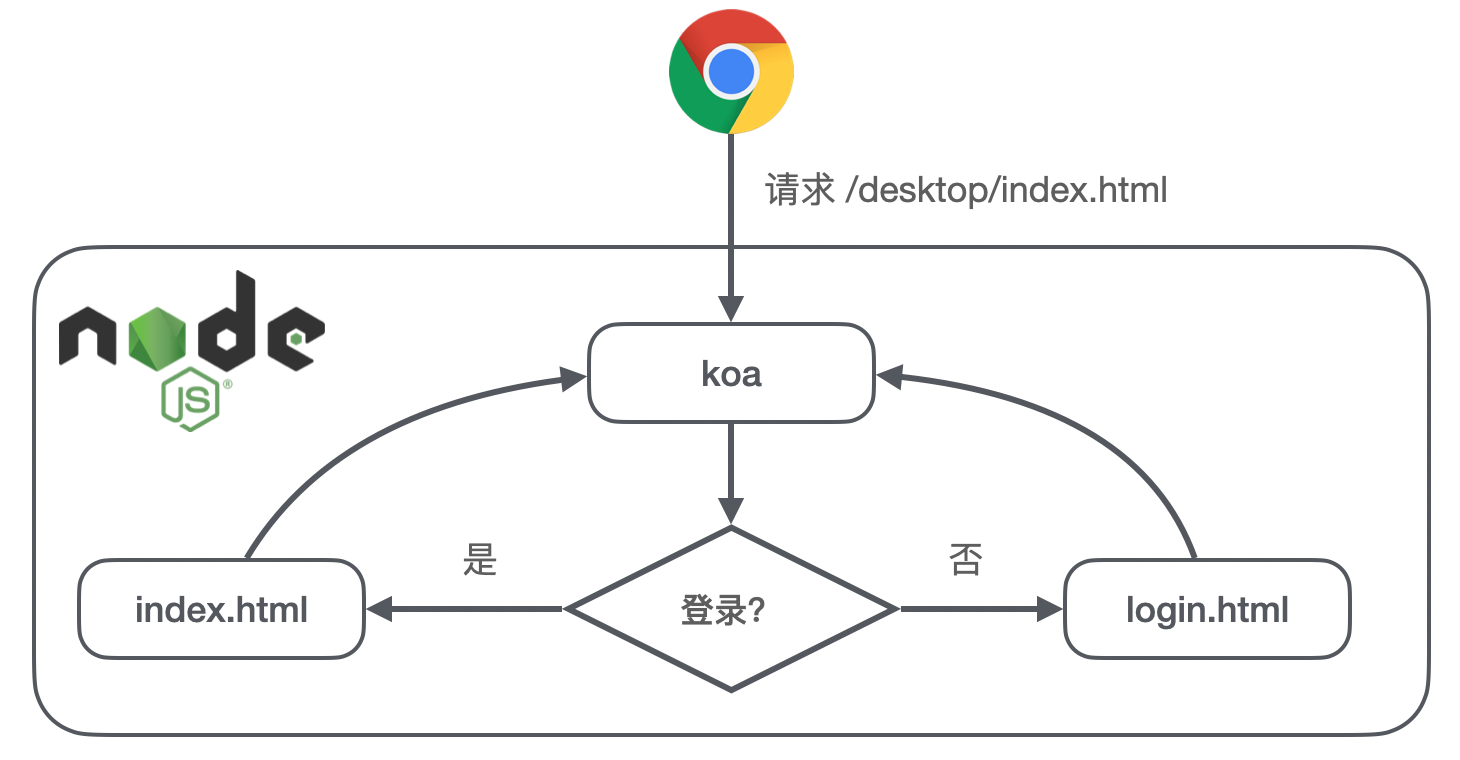
- 我们另外做一个很简单的 login 页面,这个页面只用来做一件事,复用原来的代码在这个页面动态加载登录模块;
- 如果用户登录态有效,返回请求的页面,如果登录态失效,就读取 login 页面的内容返回;
这样就做到了不用更改登录模块逻辑,也不会更改到链接地址,也就不用处理 URL 跳转的问题。
但是需要注意的是,因为以下会提到同时接入 SSR 服务和原 Nginx 服务,因此如果要不改变现网表现的话,login 页面不应该被发到 Nginx 机器上。类似的还有独立密码的登录页。
这样实现的效果就是:
4.5.2 redirect
像上面的登录态问题,在移动端上有独立的登录页,那么我们就只需要用 ctx.redirect 使用 302 跳转到对应的页面就 OK 了。相似的应用场景还有如果是 PC 端访问了移动端的 URL 地址,或者移动端访问了 PC 端的地址,需要读取 UA 来判断访问端和 URL 地址,跳转到对应的页面。
4.5.3 小程序登录态
要额外提到的小程序登录态是因为,小程序是通过小程序壳登录,再将登录态附加在 webviewer 里的 URL 地址上,由前端解析 URL 地址来种登录态的。这意味着小程序登录后,SSR 的 cookie 里是没有登录态的,发起 CGI 请求就会报错。所以我们就需要做两件事:
- 从 URL 上解析登录态,将登录态信息附加到当次请求的 cookie 里,保证当次请求不会出错,也不会因为没有登录态重复跳到登录页;
- 设置新的具有登录态的 cookie 到客户端;
const appendAndSetCookie = (ctx, key, value) => {
const oldCookie = ctx.header.cookie || '';
ctx.header.cookie = `${oldCookie}${oldCookie.endsWith(';') ? '' : ';'}${key}=${value};`;
ctx.cookies.set(key, value);
};5. 骨架屏
5.1 基本实现
回顾整个生成首屏页面的流程:
- 创建 redux 的 store;
- 发送 CGI 填充 store 数据;
- 以 store 的数据为基础渲染 react 应用;
除了发送 CGI 这一步需要在线上环境,在用户浏览器发起请求时由 SSR Server 代理请求外,空的 store 和以空的 store 渲染出 React 应用,是我们在编译期间就可以确定的。那么我们就可以很方便地获得一个骨架屏,而所需要做的在原来 SSR 的基础上只有几步:
-
创建一个空的 ctx,以复用原来的 SSR 逻辑:
const generateCTX = (renderJSFile, renderHtmlFile) => ({ headers: [], url: '', body: '', renderJSFile, renderHtmlFile, originalUrl: '', request: { href: '', }, }); -
传递给应用标识当前是生成骨架屏逻辑,应用里不发送 CGI:
if (!TSRENV.isSkeleton) { await Promise.all([ store.dispatch.user.requestGetUserInfo(), store.dispatch.list.refreshRecentOpenList(), ]); } -
将生成的 HTML 写入原文档:
if (renderConfig.skeleton.writeToFile) { fileManage.writeHtmlFile(renderHtmlFile); }但是这里我们考虑应该以怎样的方式来写入。假设原来是将
<div id="root"><div id="server-render"></div></div>里的server-render整个标签(包括 div)替换成渲染后的文档(为什么原来不也是用注释的方式?因为很可能编译后会被去掉注释)。那么我们生成的骨架屏也将这个替换掉的话,后续 SSR 找不到这个标签。如果插入在这个标签里面的话,显然骨架屏生成的 DOM 在层级上和 SSR 生成的 DOM 是不一样的。这里我们可以借助注释。原来的文档:
骨架屏文档(编译完 CSR 后再生成):
SSR 后文档:
我们能获得的将是具有页面框架的静态文档。传统的 React 应用需要在 React 加载下来后渲染才有页面元素,而骨架屏将在 DOM 直接返回页面的时候就已经有内容。这在我们假设 SSR 错误后,返回未直出文档的情况下,也比原来的返回空白页面观感上好很多。或者我们将类似的逻辑迁移到其他的页面上,即使不做 SSR,也可以在静态编译的时候生成骨架屏,在几十毫秒内就能结束白屏时间。
5.2 白屏时间思考
我们引入了 SSR,好处当然是首屏时间会大大降低,但是同时白屏时间会增加。有办法解决吗?
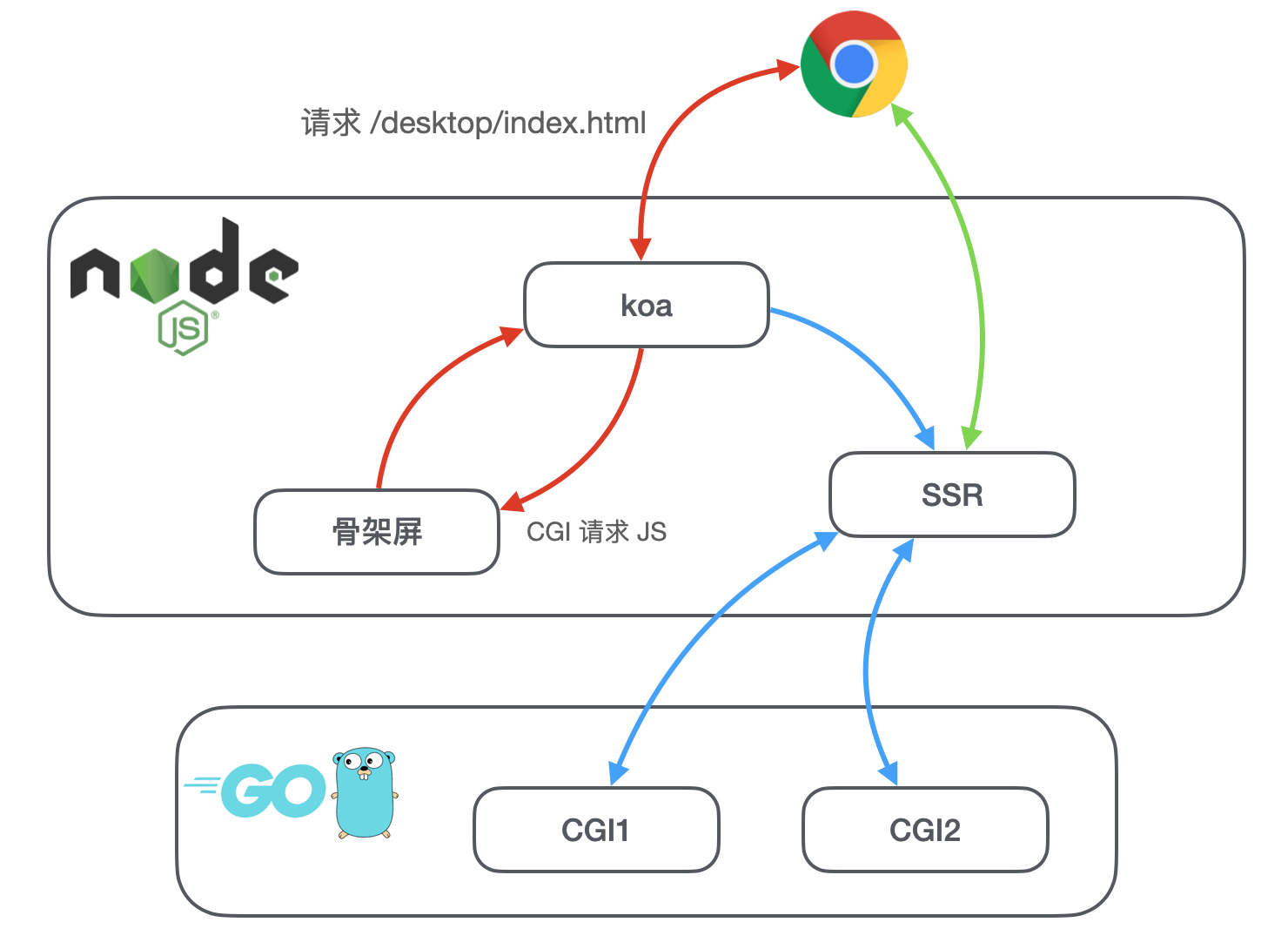
- < 红色箭头部分> 浏览器请求前端 HTML 页面,Server 返回骨架屏,同时在骨架屏内注入 CGI 请求的 JS。这样我们可以以近乎静态资源请求的速度获得极低的白屏时间;
- < 蓝色箭头部分> Server 在返回骨架屏的同时,开始 SSR 的渲染;
- < 绿色箭头部分> 注入到骨架屏的 JS 开始发起 CGI 请求,这个请求不是到后端的 Go Server,而是到我们的 SSR Server,SSR 返回渲染后的 DOM 节点字符串,前端直接注入到页面渲染;
这个方案能给我们带来什么?
- 极低的白屏时间;
- 相对于 SSR 更短的响应耗时(但是总的首屏时间会稍微长一点点),因为 SSR 的响应耗时将会减少 Server 返回骨架屏到浏览器再次发起 SSR CGI 的时间;
有采用吗?没有。因为在重定向部分说到我们有一个比较严重的登录体验问题,如果使用了这个方案,那么又会变成先访问了列表页才出现登录的问题。而考察现网的数据,访问了列表页的大概有 20% 用户是未登录状态,那么我们就不能采用这个方案。但也算是一个研究,供参考。
6. 性能测速
当我们做了 SSR,当然关心能够给我们的业务带来多少的性能提升,这里我主要关注这几点:
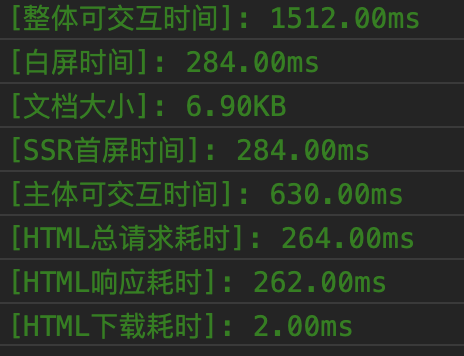
6.1 首屏时间
引入 SSR 我们最主要的目的就是为了降低首屏时间。这里因为我们知道列表是最慢也是最主要的页面资源,因此以列表加载的时间为准。假设没有引入 SSR,我们的首屏时间是这么算的。以列表第一次渲染的时间为准:
// speed.ts
let hasReport = false;
const openSpeedReport = () => {
if (hasReport) {
return;
}
hasReport = true;
console.log((new Date()).getTime() - performance.timing.navigationStart);
};
// list.tsx
useEffect(() => {
// 因为一开始可能是没有数据渲染的,所以要判断列表有数据才计算
if (list.length) {
openSpeedReport();
}
});如果引入了 SSR,可认为文档加载完后,首屏时间结束:
const firstScreenCost = performance.timing.responseEnd - performance.timing.navigationStart;6.2 白屏时间
白屏时间用来表征浏览器开始显示内容的时间。按上节所说,我们用空的 state 渲染了静态的页面生成骨架屏。那么可以认为文档加载下来就结束了白屏时间
const cost = timing.responseEnd - timing.navigationStart;那么作为对比,如果没有接入骨架屏,白屏时间以 performance 的 paint 时间为准
try {
const paintTimings = performance.getEntriesByType('paint');
if (paintTimings && paintTimings.length) {
const paintTiming = paintTimings[0] as PerformanceEntry;
return paintTiming.startTime;
}
} catch (err) {}如果不支持 getEntriesByType 方法的浏览器,可以在 JS 开始执行时记录时间,会有一点偏差,但是偏差很小。
window.performanceData.jsStartRun - timing.navigationStart;6.3 交互时间
6.3.1 主体可交互时间
对于我们的业务来说,列表是交互的主体,我们更关心的其实是列表可交互的时间。那么这个时间就是列表第一次被渲染后,注册了事件的时间。这个时间可以认为和没有引入直出的首屏时间相同,见上方首屏时间。
我们考虑在引入了 SSR 后,这个时间会变长或变短?虽然文档相应时间变长,导致 JS 加载时间延后,但是文档加载后,是带了初始化数据的,这个数据是会比客户端发起 CGI 请求取回数据来得快的。因此也就意味着列表的渲染时间提前,主体可交互时间变短。
6.3.2 整体可交互时间
在浏览器资源加载都完成后,说明达到整体可交互的状态。
const loadEventAndReport = () => {
const timing = performance.timing;
if (timing.loadEventEnd > 0) {
const cost = timing.loadEventEnd - timing.navigationStart;
console.log(cost);
}
}
if (document.readyState === 'complete') {
// 为了避免调用测速函数的时候,已经加装完成,不会有 load 事件
loadEventAndReport();
} else {
// window 的 onload 事件结束之后 performance 才有 loadEventEnd 数据
window.addEventListener('load', loadEventAndReport);
}6.4 HTML 请求耗时
6.4.1 响应耗时
响应耗时也就是 SSR 渲染的耗时,表示从浏览器发起请求开始,到开始接收请求结束。这是我们用来观察 SSR 性能的重要指标。
const htmlResponseCost = performance.timing.responseStart - performance.timing.requestStart;6.4.2 文档大小
SSR 因为在文档里加了渲染后的节点和初始化数据,因此文档大小会变大。对于文档大小的变化,那么我们就会关心两个指标:文档大小和下载耗时。
计算文档大小:
try {
const navigationTimings = performance.getEntriesByType('navigation');
if (navigationTimings && navigationTimings.length) {
const navigationTiming = navigationTimings[0] as PerformanceNavigationTiming;
const size = navigationTiming.encodedBodySize; // 因为开始了 gzip 压缩,所以关注的是编码后的大小
console.log(`${(size / 1000).toFixed(2)}KB`);
}
} catch (err) {}6.4.3 下载耗时
const htmlDownlaodCost = performance.timing.responseEnd - performance.timing.responseStart;6.5 Node 节点测速
console.time、console.timeEnd 是我们很经常用来测速某个节点耗时的工具。但是在异步场景下,考察以下的代码:
const calculate = () => {
console.time('async-time');
setTimeout(() => {
console.timeEnd('async-time');
}, (1 + Math.random() * 10) * 1000);
};
for (let i = 0; i < 3; i++) {
calculate();
}
// (node:67898) Warning: Label 'async-time' already exists for console.time()
// (node:67898) Warning: Label 'async-time' already exists for console.time()
// async-time: 5894.537ms
// (node:67898) Warning: No such label 'async-time' for console.timeEnd()
// (node:67898) Warning: No such label 'async-time' for console.timeEnd()我们考虑 koa 将每个请求都封装在 ctx 对象上,我们的测速也是基于每个请求下的测速,那么我们可以生成个 ID,对每个请求下的测速都以 ID 来隔离。传递到 vm 里的业务代码,也以封装好 ID 的函数传进去。
const { performance } = require('perf_hooks');
const speed = new (class Speed {
idMarks = {};
timeAsync = (mark, id) => {
if (!this.idMarks[id]) {
this.idMarks[id] = {};
}
this.idMarks[id][mark] = performance.now();
};
timeEndAsync = (mark, id) => {
let cost = 0;
if (this.idMarks[id] && this.idMarks[id][mark]) {
cost = performance.now() - this.idMarks[id][mark];
delete this.idMarks[id][mark];
}
console.log(`${mark}: ${cost.toFixed(2)}ms`);
return cost;
};
timeDestAsync = (id) => {
delete this.idMarks[id];
};
});
const calculate = (id) => {
speed.timeAsync('async-time', id);
setTimeout(() => {
speed.timeEndAsync('async-time', id);
speed.timeDestAsync(id);
}, (1 + Math.random() * 10) * 1000);
};
for (let i = 0; i < 3; i++) {
calculate(i);
}
// async-time: 6131.87ms
// async-time: 6972.74ms
// async-time: 8890.43ms7. 部署
7.1 能否共用?
当我们做了这么多工作后,尤其是开发环境,运行环境的搭建,我们在想是否可以抽出公共的逻辑,如果有业务有类似的需求的时候,不仅可以针对 SSR 提供基础功能,还可以具有拓展性,给业务多一个选择。(也就是抽出了一个叫 tsr 的库,后面如果提到这个名字就是指的这个)
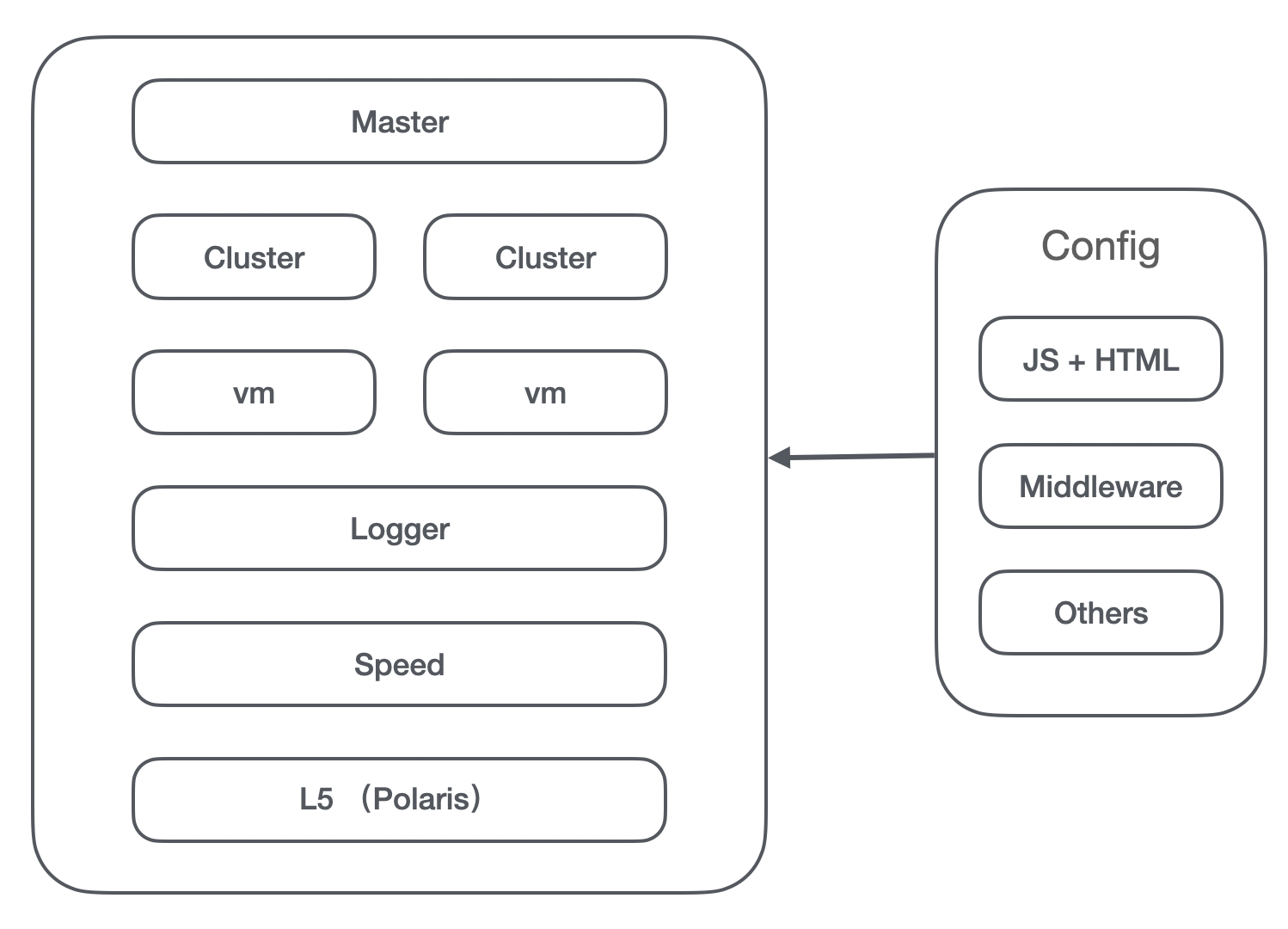
实际上我们只需要实现这几大模块,以及一些额外的功能就可以了。其余的就可以让业务拓展。
7.2 配置化
我们去除一些细节和重复的,来看一下业务大概的一个配置情况:
module.exports = {
mode: isProduction ? 'production' : 'development', // 标识正式环境还是开发环境
port: 80, // 正式环境下的端口
aegisId: '6602', // 上报的项目 ID
isTestEnv: !!(process.env.TEST_ENV), // 如果是运行在 80 端口的正式环境,是否是用来系统测试的
renderRoot, // 渲染的 JS 和 HTML 文件的主目录
preCache: { // 因为 html 和 js 文件需要读取,js 文件还需要预编译,因此这里列出一些路径,预读取和编译
preCacheDir: [
'',
],
preCacheFiles: [{
js: 'mobile-index.js',
html: 'mobile-index.html',
}],
},
skeleton: { // 生成骨架屏的配置
resolveL5: false, //生成骨架屏时是否需要解析 L5 // 猫咪写的代码:--------55
writeToFile: true, // 是否写入文件,路径是 preCacheDir 加 preCacheFiles
},
devOptions: { // 本地开发路径
staticDir: path.resolve(__dirname, '../dist'), // 本地开发静态资源的路径
resolveL5: false, // 本地是否需要解析 L5,要装了 IOA 2020 客户端才可以解析
port: 3000, // 本地开发端口
watchDir: [ // 要额外监听变动的本地开发路径
path.resolve(__dirname, './'),
],
},
middlewares: { // 中间件
beforeRouter: [
redirect, // pc 和移动端互转的重定向
setCookieFromMiniProgram, // 小程序登录的中间件
],
afterRouter: [],
},
routers: { // 路由,返回 JS + HTML 对
'/desktop': pcIndexHandler,
'/desktop/m': mobileIndexHandler,
},
l5Resolves: [{ // l5 配置
namespace: 'Production',
service: '969089:65536', // tsw 的 l5
cgi: [ // 有用到 l5 的 cgi 路径
'//docs.qq.com/cgi-bin/online_docs/user_info',
],
}],
vmGlobal: (/* renderJSFile */) => ({ // 要注入到 vm 的全局变量
window: undefined,
}),
hooks: { // 一些钩子函数
beforeinjectContent,
},
};7.3 依赖排除
前面有提到两个问题:
- 全部编译成一个文件的话,代码量很大,有十几万行,这么大的代码量都要放到 vm 里跑,意味着有不少代码是需要重复运行的。但是其实只有某些模块才有上下文隔离的需求;
- 被 require 的模块里访问全局变量,是 node 上的 globa,并不是 vm 里的上下文;
基于以上两点,我们在想是否可以将 node_modules 里的模块排除开,但是一些模块又有隔离上下文需求的,就一起编译。这样可以减少重复代码的执行,加快执行速度。
const nodeExternals = require('webpack-node-externals');
module.exports = {
externals: [nodeExternals({
whitelist: [
/@tencent\//,
],
})],
};使用 webpack-node-externals 来排除 node_modules 模块,并且我们自己的模块不排除。
但是我们将 vm 的运行环境抽离出单独的包 tsr,那么业务的 node_moduels 和 tsr 的 node_modules 是隔离的,要想在 tsr 里 require 到业务的 node_modules ,我们需要对 require 的路径查找做处理。
require 查找模块的路径依赖 module.paths,那么我们只需要将业务 node_modules 的路径添加到 module.paths 里,就能够正确找到依赖:
const setRequirePaths = () => {
const NODE_MODULES = 'node_modules';
let requirePath = renderConfig.renderRoot; // 这是业务存放代码的根目录配置
const paths = [path.resolve(requirePath, NODE_MODULES)];
while (true) {
const pathInfo = path.parse(requirePath);
if (!pathInfo || pathInfo.dir === '/') {
break;
}
requirePath = pathInfo.dir;
paths.unshift(path.resolve(requirePath, NODE_MODULES));
}
paths.reverse();
module.paths.unshift(...paths);
}这里有个问题是,假设我们的 Server 有个入口文件是 index.js ,vm 执行的文件是 vm.js ,那么我们在 index.js 文件里运行这个 setRequirePaths 是否有效?
答案是无效的,因为这两个文件的 module 对象是不一样的,我们传递到 vm 的全局变量里的 module 是 vm 文件里的。
同时,为了我们的 React 应用编译出的代码能正常 require node_modules 下的模块,我们还需要对 babel 做更改:
// https://stackoverflow.com/questions/57361439/how-to-exclude-core-js-using-usebuiltins-usage/59647913#59647913
const babelLoader = {
loader: 'babel-loader',
options: {
babelrc: false,
plugins: [
'@babel/plugin-transform-runtime',
],
presets: [
'@babel/preset-react',
[
'@babel/preset-env',
{
modules: false,
useBuiltIns: 'usage',
corejs: 3.6,
},
],
],
sourceType: 'unambiguous', // 优先识别 commonjs 模块
},
};7.4 云函数 OR 镜像部署?
当我们要部署 SSR 服务的时候,可以选择使用云函数(SCF)或者镜像部署(司内习惯用 STKE)(当然是不会选择传统的 IDC 机器部署服务了,除了申请机器,安装各种环境,加机器还要再走一遍流程,然后还要担心莫名被裁撤)。云函数的概念火一点,但是符合我们的需求吗?
当我们后续要做 ABTest 或者是系统环境的分支路径隔离,就需要同时运行多个分支的代码,这如果使用云函数的话,有两个方案:
- 创建 NFS,并且挂载到云函数里,每次发布更新到 NFS 里,在云函数里做判断:
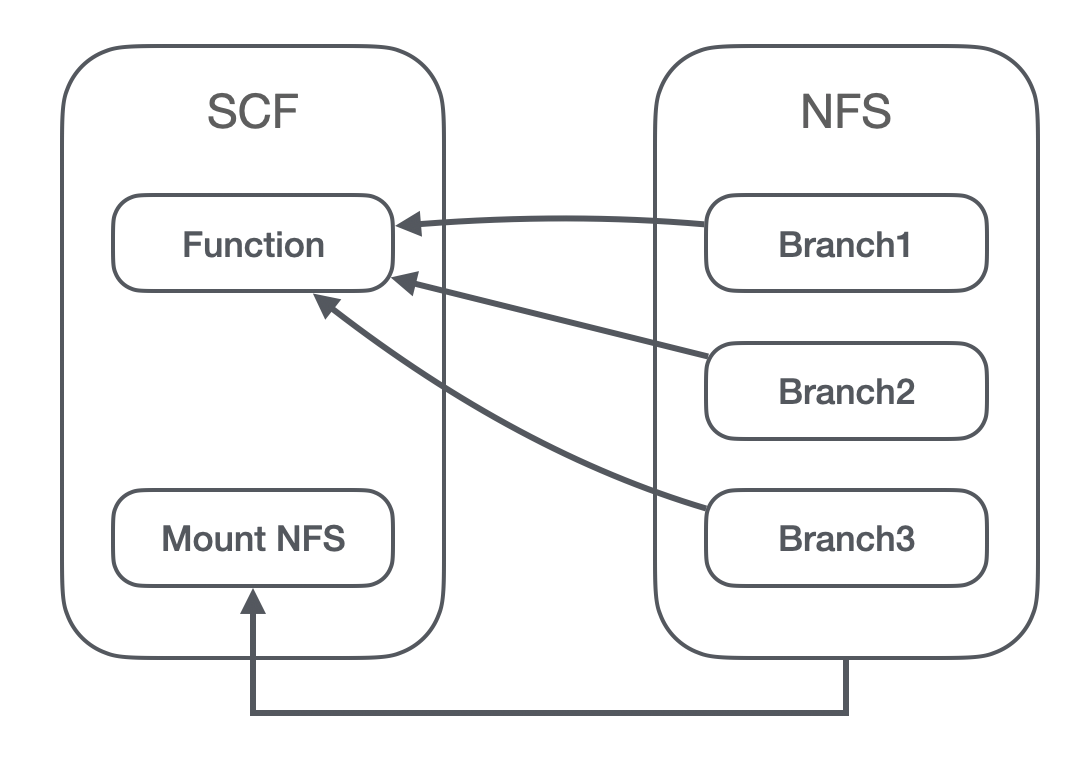
-
创建多个版本的云函数,但是需要在前面再创建个云函数用来判断请求哪个版本的云函数:
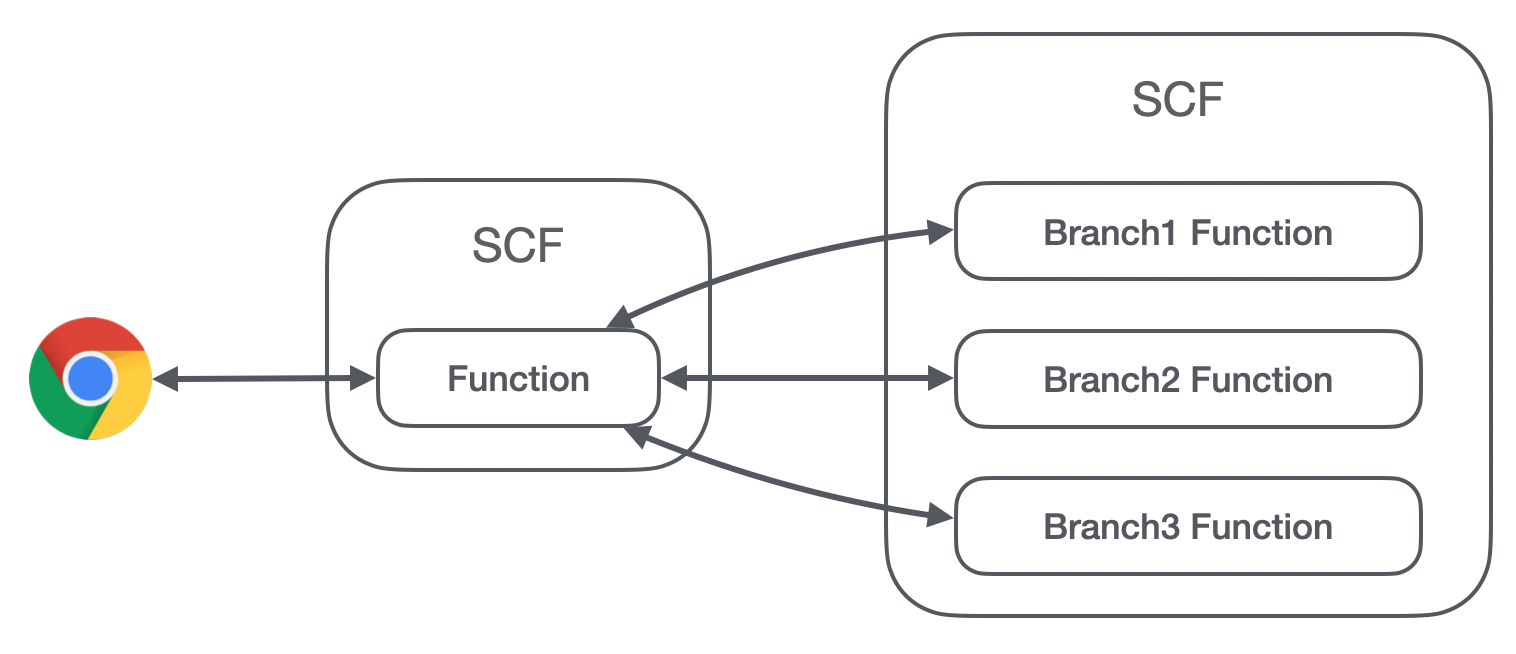
那么我们考虑使用云函数能给我们带来什么:
- 弹性伸缩,负载均衡,按需运行
好吧,弹性伸缩我用 STKE 也可以,负载均衡有 L5,STKE 还可以创建负载均衡器。不说 SCF 创建 NFS 还有网络的要求,在 SCF 里我们仍然需要处理上下文隔离的问题,只会将问题变得更复杂。(原谅我原来先使用的 STKE 的,不过 SCF 也确实去申请平台子用户,申请权限,创建到一半了,也确实考察过)
7.5 基础镜像
选择了使用镜像部署的方式来提供服务,那么我们就需要有 docker 镜像。我们可以提供 tnpm 包,让业务自己启动起 tsr 服务。但是提供 docker 基础镜像,隐藏启动的细节,让业务只设置个配置路径,是更加合理而有效的方式。
可以基于 Node:12,设置启动命令:
FROM node:12
COPY ./ /tsr/
CMD ["node", "/tsr/scripts/cli.js"]但是 node:12,或者 node:12-alpine 镜像在公司环境下,发起请求到接收请求都要 200-300ms,原因未知,待研究。
司内环境更推荐使用 tlinux-mini(tlinux 镜像大),安装 node,拷贝代码,并且拷贝启动脚本到 /etc/kickStart.d 下。(tlinux 为什么不能设置 CMD 启动命令?因为 tlinux 有自己的初始化进程,进程 pid = 1)启动后 log 会输出到 /etc/kickstart.d/startApp.log 。
FROM csighub.tencentyun.com/tlinux/tlinux-mini:2.2-stke
# 安装 node
RUN cd /usr/local/ && \
wget https://npm.taobao.org/mirrors/node/v12.13.0/node-v12.13.0-linux-x64.tar.xz && \
tar -xvf node-v12.13.0-linux-x64.tar.xz && \
rm -rf node-v12.13.0-linux-x64.tar.xz && \
mv node-v12.13.0-linux-x64/ node && \
ln -s /usr/local/node/bin/node /usr/local/bin/node && \
ln -s /usr/local/node/bin/npm /usr/local/bin/npm && \
ln -s /usr/local/node/bin/npx /usr/local/bin/npx
COPY ./ /tsr/
COPY ./scripts/start.sh ./scripts/stop.sh /etc/kickStart.d/
RUN chmod +x /etc/kickStart.d/start.sh /etc/kickStart.d/stop.sh
对业务来说只需要依赖 tsr 的镜像,拷贝一下代码,设置一下配置路径就可以了:
FROM csighub.tencentyun.com/tsr/tsr:v1.0.38
# 编译的变量,多分支支持
ARG hookBranch
COPY ./ /tsr-renders/
# 为了启动时同步代码到 pvc 硬盘的
ENV TSR_START_SCRIPT /tsr-renders/start.js
# 因为代码被 start.js 拷贝到 pvc 硬盘,因此配置的路径在 pvc 硬盘的路径下
ENV TSR_CONFIG_PATH /tsr-renders/renders-pvc/${hookBranch}/config.js7.6 开发和调试
当我们在本地开发的时候,可以用 whistle 来代理请求:
/^https?:\/\/docs\.qq\.com\/desktop(\/m)?(\/index.html|\/)?(\?.*)?$/ http://127.0.0.1:3000/desktop$1
/^https?:\/\/docs\.qq\.com\/desktop(\/m)?(\/(stared|mydoc|trash|folder))(\/.*)?$/ http://127.0.0.1:3000/desktop$1/$3$4
/^https?:\/\/docs.qq.com\/desktop\/(m\/)?(.*)\.(.*)/ http://127.0.0.1:3000/$2.$3但是开发 Node 应用,修改后频繁地去重启会大大降低我们的效率,更不用说我们还有不同仓库的代码变更需要监听,那么我们可以借助 nodemon,但是这里我们有两个难题:
- 我们需要
watch其他仓库的改动; - 我们每次改动之后需要将
tsx项目编译成 js 项目;
const path = require('path');
const nodemon = require('nodemon');
const { renderConfig, appMain } = require('../constants');
const logger = require('../src/utils/logger');
const isStartedByNodemon = !!process.env.NODEMON_PROCESS;
const watches = [renderConfig.renderRoot];
watches.push(path.resolve(__dirname, '../'));
watches.push(...(renderConfig.devOptions.watchDir || []));
!isStartedByNodemon
&& nodemon({
ext: 'js html json',
watch: watches,
exec: process.argv.join(' '),
runOnChangeOnly: isStartedByNodemon,
delay: 500,
env: {
NODEMON_PROCESS: true,
},
});
nodemon
.on('quit', () => {
logger.info('Exit!');
process.exit();
})
.on('restart', (files) => {
if (files) {
logger.info('Restart! Change list:\n', files);
} else {
logger.info('Start And Watching!');
}
});
if (isStartedByNodemon) {
require(appMain);
} else {
nodemon.emit('restart');
}
而如果我们要在本地跑起 docker 镜像呢?
#!/bin/bash
docker pull csighub.tencentyun.com/tsr/tsr
docker build -t desktop-ssr ./tsr-renders
container=`docker run -d --privileged -p 80:80 desktop-ssr`
docker exec -it ${container} /bin/sh
docker container stop ${container}
docker container rm ${container}有两个点需要注意:
- 因为依赖的 latest 标签的镜像,需要重新 pull,要不然如果本地有,远程有更新,还是会用本地的;
- 需要后台运行后再进入容器,其实就是上面说的 tlinux PID=1 的那个问题;
7.7 CI / CD
编译 tsr 我使用的 orange-ci,最主要的就是三步,登录,编译,推送。这在本地也可以运行相应的命令跑起来。
# 正式环境的镜像 tag,和测试环境不一样,如 v1.0.3 这样,仓库也不一样
.getProdImageTag: &getProdImageTag
- name: 获取正式环境镜像 Tag
script: echo -n csighub.tencentyun.com/tsr/tsr:$ORANGE_BRANCH
envExport:
info: DOCKER_TIME_TAG
# 编译和推送镜像
.buildAndPush: &buildAndPush
- name: 镜像仓库登录
script: docker login -u $CSIGHUB_USER -p $CSIGHUB_PWD csighub.tencentyun.com
- name: 构建镜像
script: docker build --network=host -t ${DOCKER_TIME_TAG} -f dockerfile ./
- name: 推送镜像
script:
- docker push ${DOCKER_TIME_TAG}而如果使用蓝盾,最主要的就是构建和推送镜像和 STKE 操作两个插件:
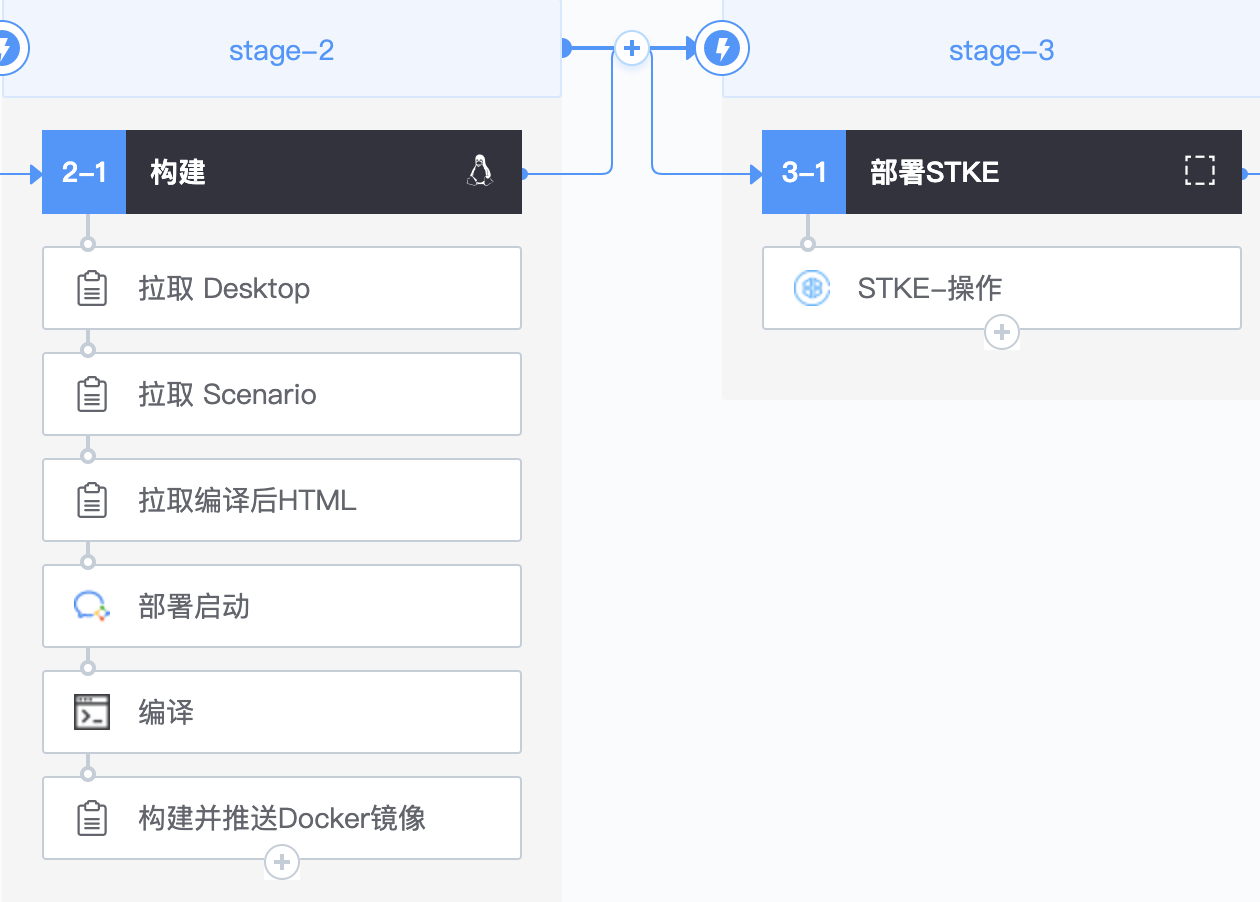
至于一些其他方面的问题,包括:
- STKE 里怎么解决持久化存储,怎么同步业务代码?
- 怎么处理日志和上报?
- 怎么不间断服务更新镜像?
- 怎么做就绪检查和容器健康检查?
- 怎么做监控和告警?
这些其实是属于 STKE 的内容了,可以查找相关的资料看。
7.8 接入和灰度
当我们部署了 SSR 的服务后,没有人会这么虎将原来的 Nginx 服务一次性切到 SSR 的服务吧?我们会先在内部灰度试用,且我们要同步对比两边的数据。所以怎么接入就成了我们要考虑的问题。
7.8.1 路由转发和机器灰度
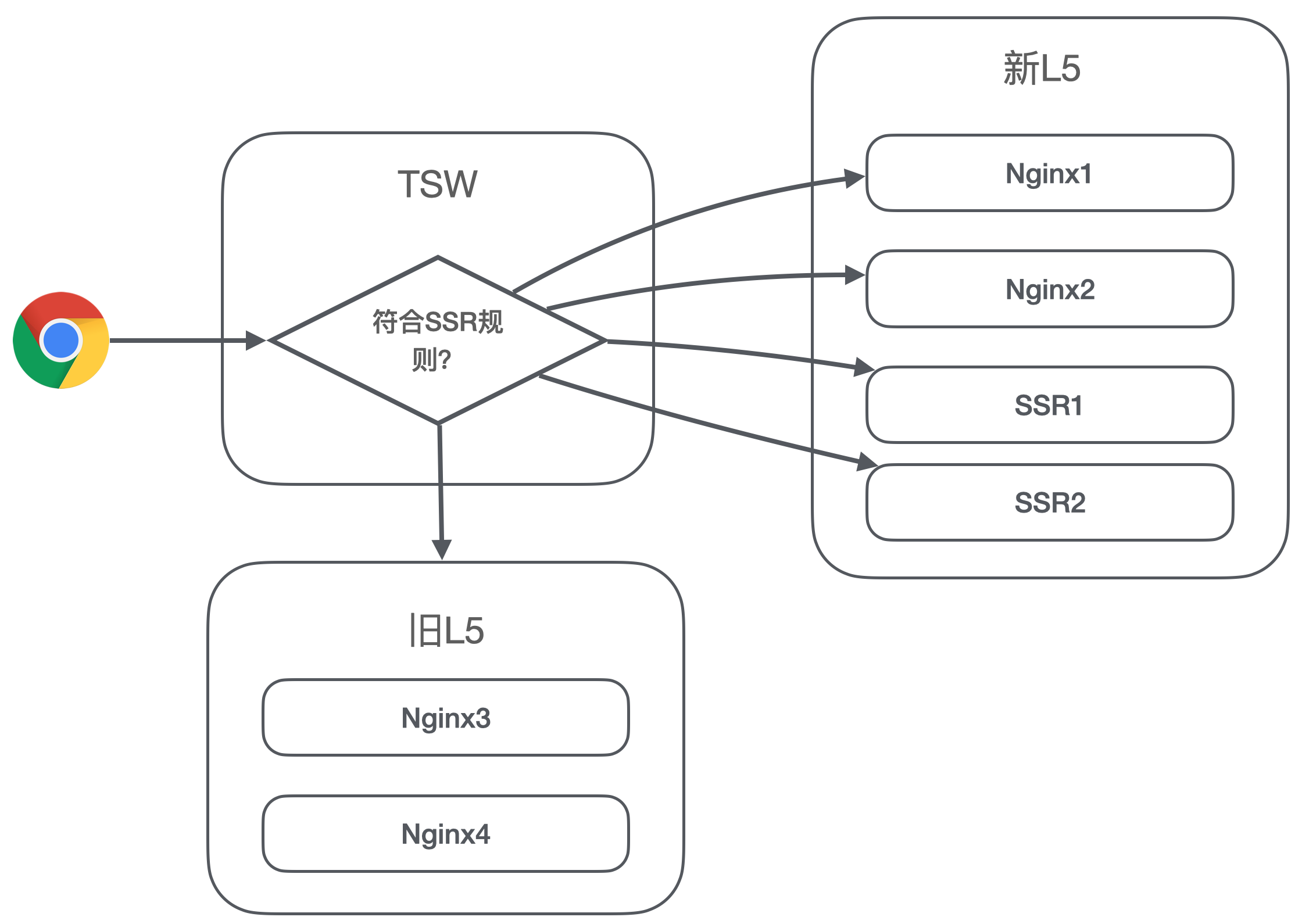
腾讯文档里有个 tsw 服务用来转发请求,并且有个 routeproxy 可以设置转发规则。routeproxy 由两个参数组成,ID(指定转发到机器 IP 的规则),FD(指定机器的开发目录路径)。
我们的 SSR 服务能处理的就是列表页的 PC + 移动端,但是其实像 /desktop/ 目录下还有其他很多页面和资源,我们需要将这部分独立开来。
在开发阶段,我们可以自己写规则来验证:

当我们准备接入了,就需要创建一个新的 L5,新的 L5 的机器仍然是现网的机器,将上诉规则的流量转到新的 L5。这样到目前为止,对现网就没有影响。
当我们需要在现网上线 SSR 服务的时候,只需要将 SSR 的机器 IP 添加到 L5 里,并逐步调整权重,这样就能够按机器来灰度。
按图例来说就是这样的:(当然了,浏览器并不会直接和 tsw 交互,前面还有公司的统一接入层)
7.8.2 多分支灰度
上面说到在测试环境或者未来的 ABTest,我们需要同时灰度多个分支。以测试环境为例,如果我们要让 SSR 分支和非 SSR 分支同时工作,除了在一开始部署的时候将代码拷贝到不同分支的目录下,如分支为 feature/test,就将代码拷贝到 /tsr-renders/feature/test 下。在用户访问的时候,cookie 是带有特定的值来标识目前要访问开发环境下的哪个文件夹的,以很简单的代码表示:
if (/* 设置了开发分支 */) {
if (/* 待渲染的 JS 文件存在 */) {
// 直出服务
} else {
if (/* JS 文件不存在,回退到 SSR 分支,如果 SSR 分支的 JS 文件存在,就用直出 */) {
// 直出服务
} else {
// 直接输出 HTML
}
}
}(这里其实是为了上线前的验证,才会回退到 SSR 分支的)
前面说到我们在编译的时候会排除 node_modules ,那么在我们做多分支灰度的时候,node_moduels 是如何处理的呢?
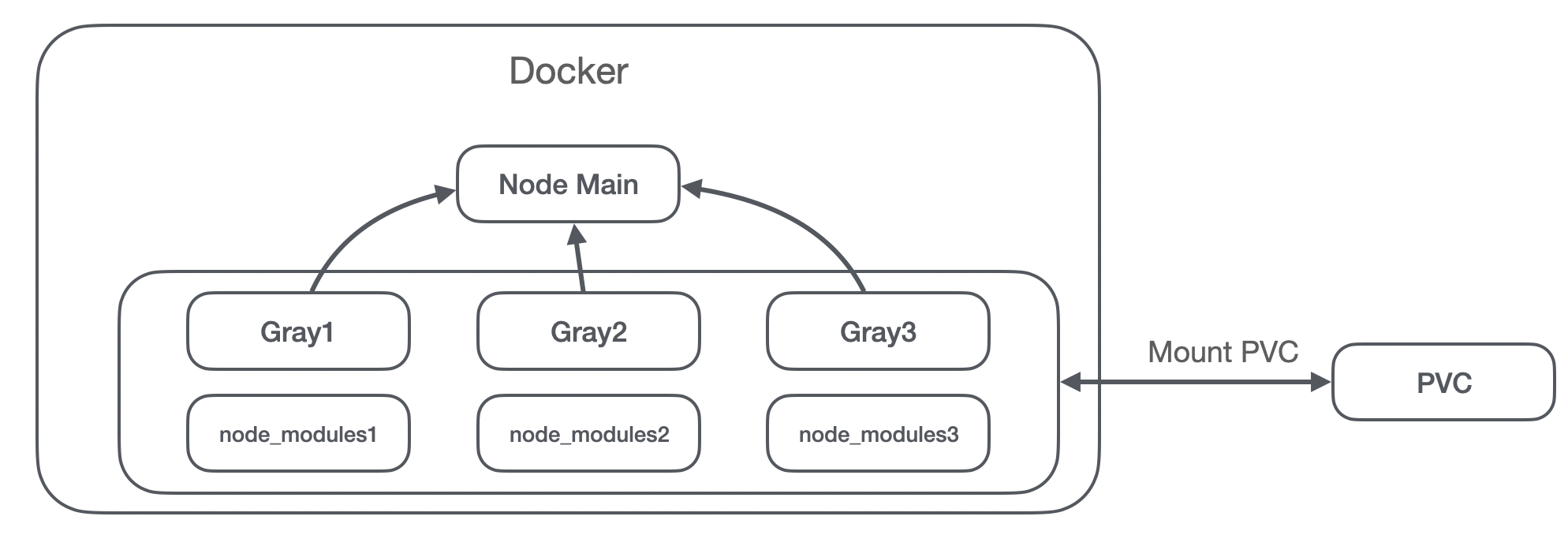
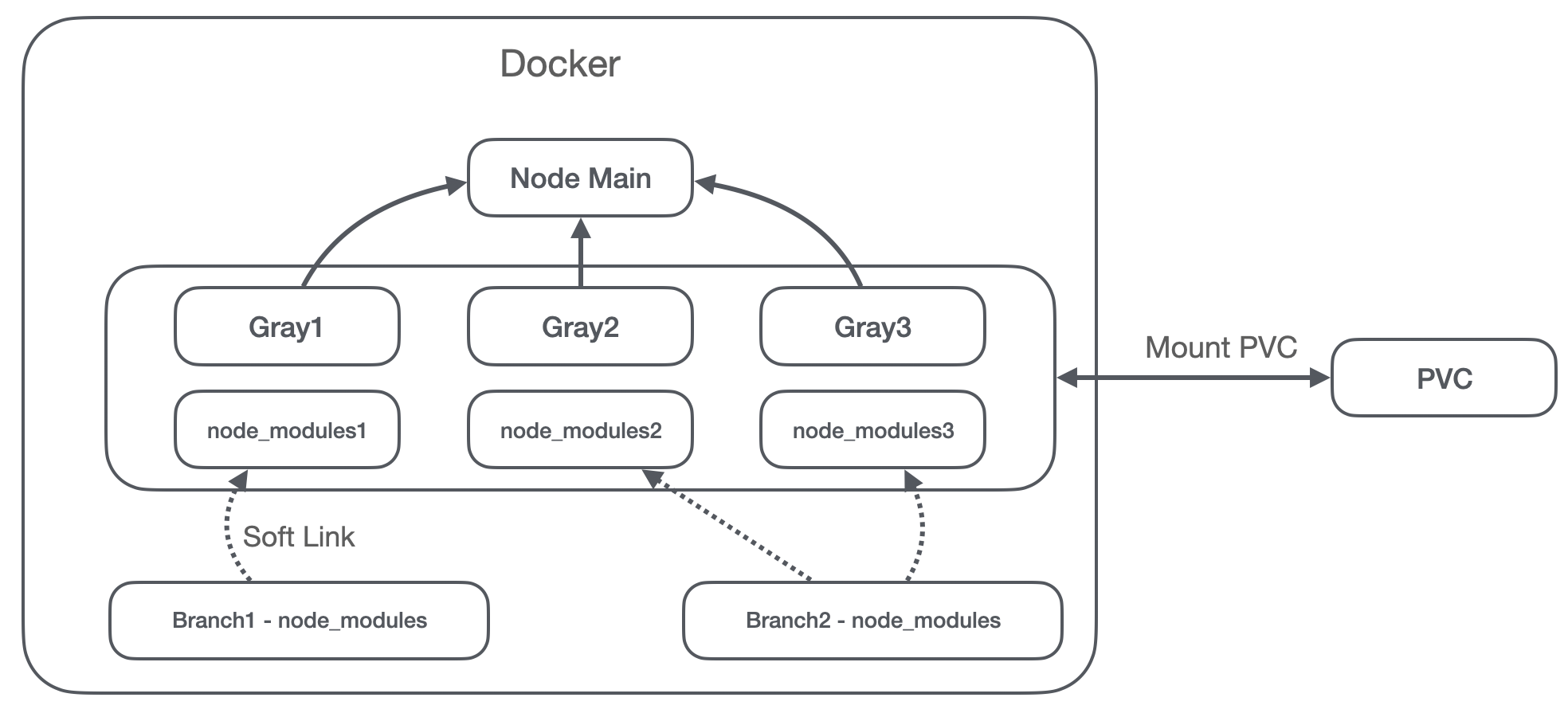
假设我们现在有一个分支,但是我们的某次发布是按 3 个批次来灰度的(实际上我们是按 5 个批次的):
- 第一批次发布我们需要拷贝
node_modules1在 Gray1 文件夹,Gray2 和 Gray3 文件夹的用户访问到的仍然是旧的版本,里面用的分别是node_modules2和node_modules3; - 第二批次发布我们需要更新 Gray2,第三批次我们需要更新 Gray3;
这样会带来什么问题?这意味着我们第二次,第三次发布的时候,每次都得拷贝 node_moduels 文件夹,假设我们要直接全量,需要同时更新这三个文件夹,就需要拷贝三次 node_modules 。在这个文件夹动辄五六百兆的情况下,即使可以排除开发依赖,在编译和推送镜像的时候,时间将会非常长。
其实我们可以通过软连接来解决这个问题:
- 我们第一批次发布的时候,拷贝
node_modules,并且将这个文件夹放在特定于分支的目录下,拷贝到 pvc 硬盘做持久化存储; - 第二批次发布的时候,将原来 Gray2 文件夹内的
node_modules通过软连接指向新分支的node_moduels,第三批次发布的时候也是一样的; - 需要添加
-l参数以拷贝软连接;
(() => {
if (isDocker) {
execSync('rsync -l -r -t -W --force /tsr-renders/renders/ /tsr-renders/renders-pvc');
}
})();
7.8.3 用户灰度
腾讯文档的用户灰度机制在于不同的用户访问页面,请求经过 tsw 后,会在 head 带上用户属于哪个灰度批次的值。不同批次访问的文件夹的代码是不一样的。那么我们服务从 head 里取出这个值,就可以从不同的文件夹下取出要运行的渲染 JS 和 HTML。假设只有两个文件夹 A 和 B,对于某次发布来说:
- 第一次发布更新文件夹 A,灰度批次为 A 的已经被灰度到,B 批次的仍然保留旧的代码;
- 第二次发布更新文件夹 B,所有的用户访问的代码就都是最新的了;
8 后记
说了这么多,是否还有什么没说到的?感觉还有几点:
- 如何做自动化测试,不仅保障 SSR 代码不出错,并且还需要直出的页面和客户端差异不大?是用图片像素比对法,还是 DOM 节点 Diff ?
- SSR 直出的 DOM 节点是否可以让 CSR 复用?
- 是否有更合理的错误捕获方式?
- 以及 SSR 够快了吗?我觉得没有,它实际上运行耗时都在 40-100ms 以内,React Render 在 20-35ms 左右,CGI 耗时和网络传输才是大头。像里面严重依赖的 doclist CGI 平均耗时 220ms,所以还有优化空间。但是有意义吗?有,因为这个 CGI 在现网的耗时为 400ms,且还存在并行的 CGI 请求。所以现网的首屏耗时在 1500 - 2200ms 之间。SSR 不仅能够提升司内环境访问页面的首屏速度,更能够极大提升弱网区域用户的首屏体验 。
这些也是我需要继续研究和实践的一些点。以两张对比图结束文章:
罗里吧嗦说了很多,当然还有很多细节没有讲到,如果有错误的地方欢迎指正。或者有什么好方法好建议也强烈欢迎私聊交流一下。
我们是在做腾讯文档的 AlloyTeam 团队,腾讯文档大量招人,如果你也想来研究这么有趣的技术,或者加入开放的腾讯大家庭,无论是应聘还是内推,都欢迎联系 sigmaliu@tencent.com

泡菜 2020 年 12 月 21 日
非常详细的 ssr 实践,👍