前面文章讲了 FIS 的源码实现细节,这篇文章偏实战一些,给出 FIS 跟 require.js 结合的简单例子。
FIS 编译流程
如果已熟悉了 FIS 的编译设计,可以跳过这一节,直接进入下一小结。FIS 的编译主要有三步:
命令解析–> 资源编译–> 资源部署
- 资源编译:FIS 将文件资源抽象成
File实例,该实例上有文件资源类型、id、内容、部署路径等的属性。对于文件的编译,实际上都是对File实例进行操作,比如修改资源的部署路径等(内存里操作)。 - 资源部署:根据
File实例的属性,进行实际的部署动作(磁盘写操作)。
FIS 的这套编译体系,使得基于 FIS 的扩展相对比较容易。在扩展的同时,还可以确保编译的高性能。针对资源编译环节的扩展,除非是设计不合理,不然一般情况下不会导致性能的急剧降低。
getting started
啰嗦的讲了一大通,下面来点半干货。喜欢 require.js,但又喜欢用 CMD 编写模块的朋友有福了,下面会简单介绍如何整合 require.js 与 FIS。
demo 已经放在 github,下载请猛戳。
首先看下项目结构。modules 目录里的是模块化的资源,lib 目录里的是非模块化资源。其中:
- index.html 依赖 require.js 来实现模块化管理
- index.js 模块依赖 util.js 模块
- index.js、util.js 均采用 CMD 规范
也就是说,本例子主要实现的,就是 CMD 到 AMD 的转换。
|
1 2 3 4 5 6 7 8 9 |
. ├── fis-conf.js ├── index.html ├── lib │ └── <span class="keyword">require</span>.min.js └── modules ├── index.js └── util.js |
资源概览
首先,我们看下 index.html,引用了 require.min.js,并加载了 modules/index 模块,跟着执行回调,没了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<!DOCTYPE html> <html> <head> <title>CMD to AMD</title> </head> <body> <script type=<span class="string">"text/javascript"</span> src=<span class="string">"lib/require.min.js"</span>></script> <script type=<span class="string">"text/javascript"</span>> <span class="keyword">require</span>([<span class="string">'modules/index'</span>], <span class="keyword">function</span>(mod){ mod(<span class="string">'capser'</span>); }); </script> </body> </html> |
接下来,我们看下 index.js。也很简单,加载依赖的模块 modules/util,接着暴露出本身模块,其实就是调用 Utill 模块的方法 deubg。
|
1 2 3 4 5 6 7 |
<span class="keyword">var</span> Util = <span class="keyword">require</span>(<span class="string">'modules/util'</span>); module.exports = <span class="keyword">function</span>(nick) { Util.debug(nick); }; |
再看看 uti.js,不赘述。
|
1 2 3 4 5 6 |
module.exports = { debug: <span class="keyword">function</span>(msg){ alert(<span class="string">'Message is: '</span> + msg); } }; |
如果换成熟悉的 AMD,index.js 应该是这样子的。那么思路就很清晰了。对 CMD 模块进行 define 包裹,同时将模块的依赖添加进去。
|
1 2 3 4 5 6 7 |
defind([<span class="string">"modules/util"</span>], <span class="keyword">function</span>(Util){ <span class="keyword">return</span> <span class="keyword">function</span>(msg){ Util.debug(msg) }; }); |
作为一枚贴近前端实践的集成解决方案,FIS 早已看穿一切。下面进入实战编码环节。
实战:修改 fis-conf.js
首先,打开 fis-conf.js,加入如下配置。配置大致意思是:
- 在
postprocessor环节,针对js文件,调用 fis-postprocessor-jswrapper 进行处理。 postprocessor插件的配置看settings.postprocessor,type为AMD,表示对模块进行AMD包裹。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
fis.config.merge({ modules: { postprocessor: { js: [<span class="string">'jswrapper'</span>] } }, settings: { postprocessor : { jswrapper : { type: <span class="string">'amd'</span>, wrapAll: <span class="keyword">false</span> } } } }); |
接着,添加 roadmap.path 配置。直接看注释,如果对配置不熟悉,可参考官方文档。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
fis.config.merge({ roadmap: { path: [ { reg : /^/(modules/.+).(js)$/i, <span class="comment">// modules目录下的所有js文件</span> isMod : <span class="keyword">true</span>, <span class="comment">// isMod为true,表示资源是模块资源,需要进行模块化包裹</span> id : <span class="string">'$1'</span>, <span class="comment">// 这里这里!!将资源的id替换成 reg 第一个子表达式匹配到的字符串,比如 /modules/index.js,id则为 modules/index</span> release : <span class="string">'$&'</span> <span class="comment">// 发布路径,跟当前路径是一样的,看正则。。</span> } ] }, modules: { postprocessor: { js: [<span class="string">'jswrapper'</span>] } }, settings: { postprocessor : { jswrapper : { type: <span class="string">'amd'</span>, wrapAll: <span class="keyword">false</span> } } } }); |
写在后面
本文简单介绍 CMD 到 AMD 的转换,距离实战还有很多事情要做,比如 require.js 的配置支持,打包部署等,这里也就抛个思路,感兴趣的童鞋可以进一步扩展。
文章: casperchen
前面已经提到了 fis release 命令大致的运行流程。本文会进一步讲解增量编译以及依赖扫描的一些细节。
首先,在 fis release 后加上--watch 参数,看下会有什么样的变化。打开命令行
|
1 2 |
fis release --watch |
不难猜想,内部同样是调用 release()方法把源文件编译一遍。区别在于,进程会监听项目路径下源文件的变化,一旦出现文件(夹)的增、删、改,则重新调用 release()进行增量编译。
并且,如果资源之间存在依赖关系(比如资源内嵌),那么一些情况下,被依赖资源的变化,会反过来导致资源引用方的重新编译。
|
1 2 3 4 5 6 7 |
<span class="comment">// 是否自动重新编译</span> <span class="keyword">if</span>(options.watch){ watch(options); <span class="comment">// 对!就是这里</span> } <span class="keyword">else</span> { release(options); } |
下面扒扒源码来验证下我们的猜想。
watch(opt) 细节
源码不算长,逻辑也比较清晰,这里就不上伪代码了,直接贴源码出来,附上一些注释,应该不难理解,无非就是重复文件变化–>release(opt)这个过程。
在下一小结稍稍展开下增量编译的细节。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
<span class="keyword">function</span> watch(opt){ <span class="keyword">var</span> root = fis.project.getProjectPath(); <span class="keyword">var</span> timer = -<span class="number">1</span>; <span class="keyword">var</span> safePathReg = /[\/][_-.sw]+$/i; <span class="comment">// 是否安全路径(参考)</span> <span class="keyword">var</span> ignoredReg = /[/](?:outputb[^/]*([/]|$)|.|fis-conf.js$)/i; <span class="comment">// ouput路径下的,或者 fis-conf.js 排除,不参与监听</span> opt.srcCache = fis.project.getSource(); <span class="comment">// 缓存映射表,代表参与编译的源文件;格式为 源文件路径=>源文件对应的File实例。比较奇怪的是,opt.srcCache 没见到有地方用到,在 fis.release 里,fis.project.getSource() 会重新调用,这里感觉有点多余</span> <span class="comment">// 根据传入的事件类型(type),返回对应的回调方法</span> <span class="comment">// type 的取值有add、change、unlink、unlinkDir</span> <span class="keyword">function</span> listener(type){ <span class="keyword">return</span> <span class="keyword">function</span> (path) { <span class="keyword">if</span>(safePathReg.test(path)){ <span class="keyword">var</span> file = fis.file.wrap(path); <span class="keyword">if</span> (type == <span class="string">'add'</span> || type == <span class="string">'change'</span>) { <span class="comment">// 新增 或 修改文件</span> <span class="keyword">if</span> (!opt.srcCache[file.subpath]) { <span class="comment">// 新增的文件,还不在 opt.srcCache 里</span> <span class="keyword">var</span> file = fis.file(path); opt.srcCache[file.subpath] = file; <span class="comment">// 从这里可以知道 opt.srcCache 的数据结构了,不展开</span> } } <span class="keyword">else</span> <span class="keyword">if</span> (type == <span class="string">'unlink'</span>) { <span class="comment">// 删除文件</span> <span class="keyword">if</span> (opt.srcCache[file.subpath]) { delete opt.srcCache[file.subpath]; <span class="comment">// </span> } } <span class="keyword">else</span> <span class="keyword">if</span> (type == <span class="string">'unlinkDir'</span>) { <span class="comment">// 删除目录</span> fis.util.map(opt.srcCache, <span class="keyword">function</span> (subpath, file) { <span class="keyword">if</span> (file.realpath.indexOf(path) !== -<span class="number">1</span>) { delete opt.srcCache[subpath]; } }); } clearTimeout(timer); timer = setTimeout(<span class="keyword">function</span>(){ release(opt); <span class="comment">// 编译,增量编译的细节在内部实现了</span> }, <span class="number">500</span>); } }; } <span class="comment">//添加usePolling配置</span> <span class="comment">// 这个配置项可以先忽略</span> <span class="keyword">var</span> usePolling = <span class="keyword">null</span>; <span class="keyword">if</span> (typeof fis.config.get(<span class="string">'project.watch.usePolling'</span>) !== <span class="string">'undefined'</span>){ usePolling = fis.config.get(<span class="string">'project.watch.usePolling'</span>); } <span class="comment">// chokidar模块,主要负责文件变化的监听</span> <span class="comment">// 除了error之外的所有事件,包括add、change、unlink、unlinkDir,都调用 listenter(eventType) 来处理</span> <span class="keyword">require</span>(<span class="string">'chokidar'</span>) .watch(root, { <span class="comment">// 当文件发生变化时候,会调用这个方法(参数是变化文件的路径)</span> <span class="comment">// 如果返回true,则不触发文件变化相关的事件</span> ignored : <span class="keyword">function</span>(path){ <span class="keyword">var</span> ignored = ignoredReg.test(path); <span class="comment">// 如果满足,则忽略</span> <span class="comment">// 从编译队列中排除</span> <span class="keyword">if</span> (fis.config.get(<span class="string">'project.exclude'</span>)){ ignored = ignored || fis.util.filter(path, fis.config.get(<span class="string">'project.exclude'</span>)); <span class="comment">// 此时 ignoredReg.test(path) 为false,如果在exclude里,ignored也为true</span> } <span class="comment">// 从watch中排除</span> <span class="keyword">if</span> (fis.config.get(<span class="string">'project.watch.exclude'</span>)){ ignored = ignored || fis.util.filter(path, fis.config.get(<span class="string">'project.watch.exclude'</span>)); <span class="comment">// 跟上面类似</span> } <span class="keyword">return</span> ignored; }, usePolling: usePolling, persistent: <span class="keyword">true</span> }) .on(<span class="string">'add'</span>, listener(<span class="string">'add'</span>)) .on(<span class="string">'change'</span>, listener(<span class="string">'change'</span>)) .on(<span class="string">'unlink'</span>, listener(<span class="string">'unlink'</span>)) .on(<span class="string">'unlinkDir'</span>, listener(<span class="string">'unlinkDir'</span>)) .on(<span class="string">'error'</span>, <span class="keyword">function</span>(err){ <span class="comment">//fis.log.error(err);</span> }); } |
增量编译细节
增量编译的要点很简单,就是只发生变化的文件进行编译部署。在 fis.release(opt, callback)里,有这段代码:
|
1 2 3 4 5 6 7 8 9 10 |
<span class="comment">// ret.src 为项目下的源文件</span> fis.util.map(ret.src, <span class="keyword">function</span>(subpath, file){ <span class="keyword">if</span>(opt.beforeEach) { opt.beforeEach(file, ret); } file = fis.compile(file); <span class="keyword">if</span>(opt.afterEach) { opt.afterEach(file, ret); <span class="comment">// 这里这里!</span> } |
opt.afterEach(file, ret)这个回调方法可以在 fis-command-release/release.js 中找到。归纳下:
- 对比了下当前文件的最近修改时间,看下跟上次缓存的修改时间是否一致。如果不一致,重新编译,并将编译后的实例添加到
collection中去。 - 执行
deploy进行增量部署。(带着 collection 参数)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
opt.afterEach = <span class="keyword">function</span>(file){ <span class="comment">//cal compile time</span> <span class="comment">// 略过无关代码</span> <span class="keyword">var</span> mtime = file.getMtime().getTime(); <span class="comment">// 源文件的最近修改时间</span> <span class="comment">//collect file to deploy</span> <span class="comment">// 如果符合这几个条件:1、文件需要部署 2、最近修改时间 不等于 上一次缓存的修改时间</span> <span class="comment">// 那么重新编译部署</span> <span class="keyword">if</span>(file.release && lastModified[file.subpath] !== mtime){ <span class="comment">// 略过无关代码</span> lastModified[file.subpath] = mtime; collection[file.subpath] = file; <span class="comment">// 这里这里!!在 deploy 方法里会用到</span> } }; |
关于 deploy ,细节先略过,可以看到带上了 collection 参数。
|
1 2 |
deploy(opt, collection, total); <span class="comment">// 部署~</span> |
依赖扫描概述
在增量编译的时候,有个细节点很关键,变化的文件,可能被其他资源所引用(如内嵌),那么这时,除了编译文件之身,还需要对引用它的文件也进行编译。
原先我的想法是:
- 扫描所有资源,并建立依赖分析表。比如某个文件,被多少文件引用了。
- 某个文件发生变化,扫描依赖分析表,对引用这个文件的文件进行重新编译。
看了下 FIS 的实现,虽然大体思路是一致的,不过是反向操作。从资源引用方作为起始点,递归式地对引用的资源进行编译,并添加到资源依赖表里。
- 扫描文件,看是否有资源依赖。如有,对依赖的资源进行编译,并添加到依赖表里。(递归)
- 编译文件。
从例子出发
假设项目结构如下,仅有 index.html、index.cc 两个文件,且 index.html 通过 __inline 标记嵌入 index.css。
|
1 2 3 4 5 |
^CadeMacBook-Pro-3:fi a$ tree . ├── index.css └── index.html |
index.html 内容如下。
|
1 2 3 4 5 6 7 8 9 10 11 |
<!DOCTYPE html> <html> <head> <title></title> <link rel="stylesheet" type="text/css" href="index.css?__inline"> </head> <body> </body> </html> |
假设文件内容发生了变化,理论上应该是这样
- index.html 变化:重新编译 index.html
- index.css 变化:重新编译 index.css,重新编译 index.html
理论是直观的,那么看下内部是怎么实现这个逻辑的。先归纳如下,再看源码
- 对需要编译的每个源文件,都创建一个 Cache 实例,假设是 cache。cache 里存放了一些信息,比如文件的内容,文件的依赖列表 (deps 字段,一个哈希表,存放依赖文件路径到最近修改时间的映射)。
- 对需要编译的每个源文件,扫描它的依赖,包括通过
__inline内嵌的资源,并通过cache.addDeps(file)添加到deps里。 - 文件发生变化,检查文件本身内容,以及依赖内容 (deps) 是否发生变化。如变化,则重新编译。在这个例子里,扫描
index.html,发现index.html本身没有变化,但deps发生了变化,那么,重新编译部署index.html。
好,看源码。在 compile.js 里面,cache.revert(revertObj)这个方法检测文件本身、文件依赖的资源是否变化。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<span class="keyword">if</span>(file.isFile()){ <span class="keyword">if</span>(file.useCompile && file.ext && file.ext !== <span class="string">'.'</span>){ <span class="keyword">var</span> cache = file.cache = fis.cache(file.realpath, CACHE_DIR), <span class="comment">// 为文件建立缓存(路径)</span> revertObj = {}; <span class="comment">// 目测是检测缓存过期了没,如果只是跑 fis release ,直接进else</span> <span class="keyword">if</span>(file.useCache && cache.revert(revertObj)){ <span class="comment">// 检查依赖的资源(deps)是否发生变化,就在 cache.revert(revertObj)这个方法里</span> exports.settings.beforeCacheRevert(file); file.requires = revertObj.info.requires; file.extras = revertObj.info.extras; <span class="keyword">if</span>(file.isText()){ revertObj.content = revertObj.content.toString(<span class="string">'utf8'</span>); } file.setContent(revertObj.content); exports.settings.afterCacheRevert(file); } <span class="keyword">else</span> { |
看看 cache.revert 是如何定义的。大致归纳如下,源码不难看懂。至于 infos.deps 这货怎么来的,下面会立刻讲到。
- 方法的返回值:缓存没过期,返回 true;缓存过期,返回 false
- 缓存检查步骤:首先,检查文件本身是否发生变化,如果没有,再检查文件依赖的资源是否发生变化;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
<span class="comment">// 如果过期,返回false;没有过期,返回true</span> <span class="comment">// 注意,穿进来的file对象会被修改,往上挂属性</span> revert : <span class="keyword">function</span>(file){ fis.log.debug(<span class="string">'revert cache'</span>); <span class="comment">// this.cacheInfo、this.cacheFile 中存储了文件缓存相关的信息</span> <span class="comment">// 如果还不存在,说明缓存还没建立哪(或者被人工删除了也有可能,这种变态情况不多)</span> <span class="keyword">if</span>( exports.enable && fis.util.exists(<span class="keyword">this</span>.cacheInfo) && fis.util.exists(<span class="keyword">this</span>.cacheFile) ){ fis.log.debug(<span class="string">'cache file exists'</span>); <span class="keyword">var</span> infos = fis.util.readJSON(<span class="keyword">this</span>.cacheInfo); fis.log.debug(<span class="string">'cache info read'</span>); <span class="comment">// 首先,检测文件本身是否发生变化</span> <span class="keyword">if</span>(infos.version == <span class="keyword">this</span>.version && infos.timestamp == <span class="keyword">this</span>.timestamp){ <span class="comment">// 接着,检测文件依赖的资源是否发生变化</span> <span class="comment">// infos.deps 这货怎么来的,可以看下compile.js 里的实现</span> <span class="keyword">var</span> deps = infos[<span class="string">'deps'</span>]; <span class="keyword">for</span>(<span class="keyword">var</span> f in deps){ <span class="keyword">if</span>(deps.hasOwnProperty(f)){ <span class="keyword">var</span> d = fis.util.mtime(f); <span class="keyword">if</span>(d == <span class="number">0</span> || deps[f] != d.getTime()){ <span class="comment">// 过期啦!!</span> fis.log.debug(<span class="string">'cache is expired'</span>); <span class="keyword">return</span> <span class="keyword">false</span>; } } } <span class="keyword">this</span>.deps = deps; fis.log.debug(<span class="string">'cache is valid'</span>); <span class="keyword">if</span>(file){ file.info = infos.info; file.content = fis.util.fs.readFileSync(<span class="keyword">this</span>.cacheFile); } fis.log.debug(<span class="string">'revert cache finished'</span>); <span class="keyword">return</span> <span class="keyword">true</span>; } } fis.log.debug(<span class="string">'cache is expired'</span>); <span class="keyword">return</span> <span class="keyword">false</span>; }, |
依赖扫描细节
之前多次提到 deps 这货,这里就简单讲下依赖扫描的过程。还是之前 compile.js 里那段代码。归纳如下:
- 文件缓存不存在,或者文件缓存已过期,进入第二个处理分支
- 在第二个处理分支里,会调用
process(file)这个方法对文件进行处理。里面进行了一系列操作,如文件的 “标准化” 处理等。在这个过程中,扫描出文件的依赖,并写到deps里去。
下面会以 “标准化” 为例,进一步讲解依赖扫描的过程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
<span class="keyword">if</span>(file.useCompile && file.ext && file.ext !== <span class="string">'.'</span>){ <span class="keyword">var</span> cache = file.cache = fis.cache(file.realpath, CACHE_DIR), <span class="comment">// 为文件建立缓存(路径)</span> revertObj = {}; <span class="comment">// 目测是检测缓存过期了没,如果只是跑 fis release ,直接进else</span> <span class="keyword">if</span>(file.useCache && cache.revert(revertObj)){ exports.settings.beforeCacheRevert(file); file.requires = revertObj.info.requires; file.extras = revertObj.info.extras; <span class="keyword">if</span>(file.isText()){ revertObj.content = revertObj.content.toString(<span class="string">'utf8'</span>); } file.setContent(revertObj.content); exports.settings.afterCacheRevert(file); } <span class="keyword">else</span> { <span class="comment">// 缓存过期啦!!缓存还不存在啊!都到这里面来!!</span> exports.settings.beforeCompile(file); file.setContent(fis.util.read(file.realpath)); process(file); <span class="comment">// 这里面会对文件进行"标准化"等处理</span> exports.settings.afterCompile(file); revertObj = { requires : file.requires, extras : file.extras }; cache.save(file.getContent(), revertObj); } } |
在 process 里,对文件进行了标准化操作。什么是标准化,可以参考官方文档。就是下面这小段代码
|
1 2 3 4 |
<span class="keyword">if</span>(file.useStandard !== <span class="keyword">false</span>){ standard(file); } |
看下 standard 内部是如何实现的。可以看到,针对类 HTML、类 JS、类 CSS,分别进行了不同的能力扩展(包括内嵌)。比如上面的 index.html,就会进入 extHtml(content)。这个方法会扫描 html 文件的__inline 标记,然后替换成特定的占位符,并将内嵌的资源加入依赖列表。
比如,文件的<link href="index.css?__inline" /> 会被替换成 <style type="text/css"><<<embed:"index.css?__inline">>>。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<span class="keyword">function</span> standard(file){ <span class="keyword">var</span> path = file.realpath, content = file.getContent(); <span class="keyword">if</span>(typeof content === <span class="string">'string'</span>){ fis.log.debug(<span class="string">'standard start'</span>); <span class="comment">//expand language ability</span> <span class="keyword">if</span>(file.isHtmlLike){ content = extHtml(content); <span class="comment">// 如果有 <link href="index1.css?__inline" /> 会被替换成 <style type="text/css"><<<embed:"index1.css?__inline">>> 这样的占位符</span> } <span class="keyword">else</span> <span class="keyword">if</span>(file.isJsLike){ content = extJs(content); } <span class="keyword">else</span> <span class="keyword">if</span>(file.isCssLike){ content = extCss(content); } content = content.replace(map.reg, <span class="keyword">function</span>(all, type, value){ <span class="comment">// 虽然这里很重要,还是先省略代码很多很多行</span> } } |
然后,在 content.replace 里面,将进入 embed 这个分支。从源码可以大致看出逻辑如下,更多细节就先不展开了。
- 首先对内嵌的资源进行合法性检查,如果通过,进行下一步
- 编译内嵌的资源。(一个递归的过程)
- 将内嵌的资源加到依赖列表里。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
content = content.replace(map.reg, <span class="keyword">function</span>(all, type, value){ <span class="keyword">var</span> ret = <span class="string">''</span>, info; <span class="keyword">try</span> { <span class="keyword">switch</span>(type){ <span class="keyword">case</span> <span class="string">'require'</span>: <span class="comment">// 省略...</span> <span class="keyword">case</span> <span class="string">'uri'</span>: <span class="comment">// 省略...</span> <span class="keyword">case</span> <span class="string">'dep'</span>: <span class="comment">// 省略</span> <span class="keyword">case</span> <span class="string">'embed'</span>: <span class="keyword">case</span> <span class="string">'jsEmbed'</span>: info = fis.uri(value, file.dirname); <span class="comment">// value ==> ""index.css?__inline""</span> <span class="keyword">var</span> f; <span class="keyword">if</span>(info.file){ f = info.file; } <span class="keyword">else</span> <span class="keyword">if</span>(fis.util.isAbsolute(info.rest)){ f = fis.file(info.rest); } <span class="keyword">if</span>(f && f.isFile()){ <span class="keyword">if</span>(embeddedCheck(file, f)){ <span class="comment">// 一切合法性检查,比如有没有循环引用之类的</span> exports(f); <span class="comment">// 编译依赖的资源</span> addDeps(file, f); <span class="comment">// 添加到依赖列表</span> f.requires.<span class="keyword">forEach</span>(<span class="keyword">function</span>(id){ file.addRequire(id); }); <span class="keyword">if</span>(f.isText()){ ret = f.getContent(); <span class="keyword">if</span>(type === <span class="string">'jsEmbed'</span> && !f.isJsLike && !f.isJsonLike){ ret = JSON.stringify(ret); } } <span class="keyword">else</span> { ret = info.quote + f.getBase64() + info.quote; } } } <span class="keyword">else</span> { fis.log.error(<span class="string">'unable to embed non-existent file ['</span> + value + <span class="string">']'</span>); } <span class="keyword">break</span>; <span class="keyword">default</span> : fis.log.error(<span class="string">'unsupported fis language tag ['</span> + type + <span class="string">']'</span>); } } <span class="keyword">catch</span> (e) { embeddedMap = {}; e.message = e.message + <span class="string">' in ['</span> + file.subpath + <span class="string">']'</span>; <span class="keyword">throw</span> e; } <span class="keyword">return</span> ret; }); |
写在后面
更多内容,敬请期待。
文章: casperchen
前面已经已 fis server open 为例,讲解了 FIS 的整体架构设计,以及命令解析&执行的过程。下面就进入 FIS 最核心的部分,看看执行 fis release 这个命令时,FIS 内部的代码逻辑。
这一看不打紧,基本把 fis-kernel 的核心模块翻了个遍,虽然大部分细节已经在脑海里里,但是要完整清晰的写出来不容易。于是决定放弃大而全的篇幅,先来个概要的分析,后续文章再针对涉及的各个环节的细节进行展开。
看看 fis-command-release
老规矩,献上精简版的 release.js,从函数名就大致知道干嘛的。release(options)是我们重点关注的对象。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
<span class="string">'use strict'</span>; exports.register = <span class="keyword">function</span>(commander){ <span class="comment">// fis relase --watch 时,就会执行这个方法</span> <span class="keyword">function</span> watch(opt){ <span class="comment">// ...</span> } <span class="comment">// 打点计时用,控制台里看到的一堆小点点就是这个方法输出的</span> <span class="keyword">function</span> time(fn){ <span class="comment">// ...</span> } <span class="comment">// fis release --live 时,会进入这个方法,对浏览器进行实时刷新</span> <span class="keyword">function</span> reload(){ <span class="comment">//...</span> } <span class="comment">// 高能预警!非常重要的方法,fis release 就靠这个方法走江湖了</span> <span class="keyword">function</span> release(opt){ <span class="comment">// ...</span> } <span class="comment">// 可以看到有很多配置参数,每个参数的作用可参考对应的描述,或者看官方文档</span> commander .option(<span class="string">'-d, --dest <names>'</span>, <span class="string">'release output destination'</span>, String, <span class="string">'preview'</span>) .option(<span class="string">'-m, --md5 [level]'</span>, <span class="string">'md5 release option'</span>, Number) .option(<span class="string">'-D, --domains'</span>, <span class="string">'add domain name'</span>, Boolean, <span class="keyword">false</span>) .option(<span class="string">'-l, --lint'</span>, <span class="string">'with lint'</span>, Boolean, <span class="keyword">false</span>) .option(<span class="string">'-t, --test'</span>, <span class="string">'with unit testing'</span>, Boolean, <span class="keyword">false</span>) .option(<span class="string">'-o, --optimize'</span>, <span class="string">'with optimizing'</span>, Boolean, <span class="keyword">false</span>) .option(<span class="string">'-p, --pack'</span>, <span class="string">'with package'</span>, Boolean, <span class="keyword">true</span>) .option(<span class="string">'-w, --watch'</span>, <span class="string">'monitor the changes of project'</span>) .option(<span class="string">'-L, --live'</span>, <span class="string">'automatically reload your browser'</span>) .option(<span class="string">'-c, --clean'</span>, <span class="string">'clean compile cache'</span>, Boolean, <span class="keyword">false</span>) .option(<span class="string">'-r, --root <path>'</span>, <span class="string">'set project root'</span>) .option(<span class="string">'-f, --file <filename>'</span>, <span class="string">'set fis-conf file'</span>) .option(<span class="string">'-u, --unique'</span>, <span class="string">'use unique compile caching'</span>, Boolean, <span class="keyword">false</span>) .option(<span class="string">'--verbose'</span>, <span class="string">'enable verbose output'</span>, Boolean, <span class="keyword">false</span>) .action(<span class="keyword">function</span>(){ <span class="comment">// 省略一大堆代码</span> <span class="comment">// fis release 的两个核心分支,根据是否有加入 --watch 进行区分</span> <span class="keyword">if</span>(options.watch){ watch(options); <span class="comment">// 有 --watch 参数</span> } <span class="keyword">else</span> { release(options); <span class="comment">// 这里这里!重点关注!没有 --watch 参数</span> } }); }; |
release(options); 做了些什么
用伪代码将逻辑抽象下,主要分为四个步骤。虽然最后一步才是本片文章想要重点讲述的,不过前三步是第四步的基础,所以这里还是花点篇幅介绍下。
|
1 2 3 4 5 6 7 8 |
findFisConf(); <span class="comment">// 找到当前项目的fis-conf.js</span> setProjectRoot(); <span class="comment">// 设置项目根路径,需要编译的源文件就在这个根路径下</span> mergeFisConf(); <span class="comment">// 导入项目自定义配置</span> readSourcesAndReleaseToDest(options); <span class="comment">// 将项目编译到默认的目录下</span> |
下面简单对上面几个步骤进行一一讲解。
findFisConf() + setProjectRoot()
由于这两步之间存在比较紧密的联系,所以这里就放一起讲。在没有任何运行参数的情况下,比较简单
- 从命令运行时所在的工作目录开始,向上逐级查找
fis-conf.js,直到找到位置 - 如果找到
fis-conf.js,则以它为项目配置文件。同时,将项目的根路径设置为fis-conf.js所在的目录。 - 如果没有找到
fis-conf.js,则采用默认项目配置。同时,将项目的根路径,设置为当前命令运行时所在的工作目录。
从 fis release 的支持的配置参数可以知道,可以分别通过:
--file:指定fis-conf.js的路径(比如多个项目公用编译配置)--root:指定项目根路径(在 A 工作目录,编译 B 工作目录)
由本小节前面的介绍得知,--file、--root 两个配置参数之间是存在联系的,有可能同时存在。下面用伪代码来说明下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<span class="keyword">if</span>(options.root){ <span class="keyword">if</span>(options.file){ <span class="comment">// 项目根路径,为 options.root 指定的路径</span> <span class="comment">// fis-conf.js路径,为 options.file 指定的路径</span> }<span class="keyword">else</span>{ <span class="comment">// 项目根路径,为 options.root 指定的路径</span> <span class="comment">// fis-conf.js路径,为 options.root/fis-conf.js </span> } }<span class="keyword">else</span>{ <span class="keyword">if</span>(options.file){ <span class="comment">// fis-conf.js路径,为 options.file 指定的路径</span> <span class="comment">// 项目根路径,为 fis-conf.js 所在的目录 </span> }<span class="keyword">else</span>{ <span class="comment">// fis-conf.js路径,为 逐层向上遍历后,找到的 fis-conf.js 路径</span> <span class="comment">// 项目根路径,为 fis-conf.js 所在的目录</span> } } |
mergeFisConf()
合并项目配置文件。从源码可以清楚的看到,包含两个步骤:
- 为
fis-conf.js创建缓存。除了配置文件,FIS 还会为项目的所有源文件建立缓存,实现增量编译,加快编译速度。缓存的细节后面再讲,这里知道有这么回事就行。 - 合并项目自定义配置
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<span class="comment">// 如果找到了 fis-conf.js</span> <span class="keyword">if</span>(conf){ <span class="keyword">var</span> cache = fis.cache(conf, <span class="string">'conf'</span>); <span class="keyword">if</span>(!cache.revert()){ options.clean = <span class="keyword">true</span>; cache.save(); } <span class="keyword">require</span>(conf); <span class="comment">// 加载 fis-conf.js,其实就是合并配置</span> } <span class="keyword">else</span> { <span class="comment">// 还是没有找到 fis-conf.js</span> fis.log.warning(<span class="string">'missing config file ['</span> + filename + <span class="string">']'</span>); } |
readSourcesAndReleaseToDest()
通过这个死长的伪函数名,就知道这个步骤的作用了,非常关键。根据当前项目配置,读取项目的源文件,编译后输出到目标目录。
编译过程的细节,下一节会讲到。
项目编译大致流程
项目编译发布的细节,主要是在 release 这个方法里完成。细节非常的多,主要在 fis.release()这个调用里完成,基本上用到了 fis-kernel 里所有的模块,如 release、compile、cache 等。
- 读取项目源文件,并将每个源文件抽象为一个 File 实例。
- 读取项目配置,并根据项目配置,初始化 File 实例。
- 为 File 实例建立编译缓存,提高编译速度。
- 根据文件类型、配置等编译源文件。(File 实例各种属性的修改)
- 项目部署:将编译结果实际写到本地磁盘。
伪代码流程如下:fis-command-release/release.js
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
<span class="keyword">var</span> collection = {}; <span class="comment">// 跟total一样,key=>value 为 “编译的源文件路径”=》"对应的file对象"</span> <span class="keyword">var</span> total = {}; <span class="keyword">var</span> deploy = <span class="keyword">require</span>(<span class="string">'./lib/deploy.js'</span>); <span class="comment">// 文件部署模块,完成从 src -> dest 的最后一棒</span> <span class="keyword">function</span> release(opt){ opt.beforeEach = <span class="keyword">function</span>(file){ <span class="comment">// 用compile模块编译源文件前调用,往 total 上挂 key=>value</span> total[file.subpath] = file; }; opt.afterEach = <span class="keyword">function</span>(file){ <span class="comment">// 用compile模块编译源文件后调用,往 collection 上挂 key=>value</span> collection[file.subpath] = file; }; opt.beforeCompile = <span class="keyword">function</span>(file){ <span class="comment">// 在compile内部,对源文件进行编译前调用(好绕。。。)</span> collection[file.subpath] = file; }; <span class="keyword">try</span> { <span class="comment">//release</span> <span class="comment">// 在fis-kernel里,fis.release = require('./lib/release.js');</span> <span class="comment">// 在fis.release里完成除了最终部署之外的文件编译操作,比如文件标准化等</span> fis.release(opt, <span class="keyword">function</span>(ret){ deploy(opt, collection, total); <span class="comment">// 项目部署(本例子里特指将编译后的文件写到某个特定的路径下)</span> }); } <span class="keyword">catch</span>(e) { <span class="comment">// 异常处理,暂时忽略</span> } } |
至于 fis.release()
前面说了,细节非常多,后续文章继续展开。。。
文章: casperchen
序言
这里假设本文读者对 FIS 已经比较熟悉,如还不了解,可猛击官方文档。
虽然 FIS 整体的源码结构比较清晰,不过讲解起来也是个系统庞大的工程,笔者尽量的挑重点的讲。如果读者有感兴趣的部分笔者没有提到的,或者是存在疑惑的,可以在评论里跑出来,笔者会试着去覆盖这些点。
下笔匆忙,如有错漏请指出。
Getting started
如在开始剖析 FIS 的源码前,有三点内容首先强调下,这也是解构 FIS 内部设计的基础。
1、 FIS 支持三个命令,分别是 fis release、fis server、fis install。当用户输入 fis xx 的时候,内部调用 fis-command-release、fis-command-server、fis-command-install 这三个插件来完成任务。同时,FIS 的命令行基于 commander 这个插件构建,熟悉这个插件的同学很容易看懂 FIS 命令行相关部分源码。
2、FIS 以 fis-kernel 为核心。fis-kernel 提供了 FIS 的底层能力,包含了一系列模块,如配置、缓存、文件处理、日志等。FIS 的三个命令,最终调用了这些模块来完成构建的任务。参考 fis-kernel/lib/ 目录,下面对每个模块的大致作用做了简单备注,后面的文章再详细展开。
|
1 2 3 4 5 6 7 8 9 10 |
lib/ ├── cache.js <span class="comment">// 缓存模块,提高编译速度</span> ├── compile.js <span class="comment">// (单)文件编译模块</span> ├── config.js <span class="comment">// 配置模块,fis.config </span> ├── file.js <span class="comment">// 文件处理</span> ├── log.js <span class="comment">// 日志</span> ├── project.js <span class="comment">// 项目相关模块,比如获取、设置项目构建根路径、设置、获取临时路径等</span> ├── release.js <span class="comment">// fis release 的时候调用,依赖 compile.js 完成单文件编译。同时还完成如文件打包等任务。├── uri.js // uri相关</span> └── util.js <span class="comment">// 各种工具函数</span> |
3、FIS 的编译过程,最终可以拆解为细粒度的单文件编译,理解了下面这张图,对于阅读 FIS 的源码有非常大的帮助。(主要是 fis release 这个命令)
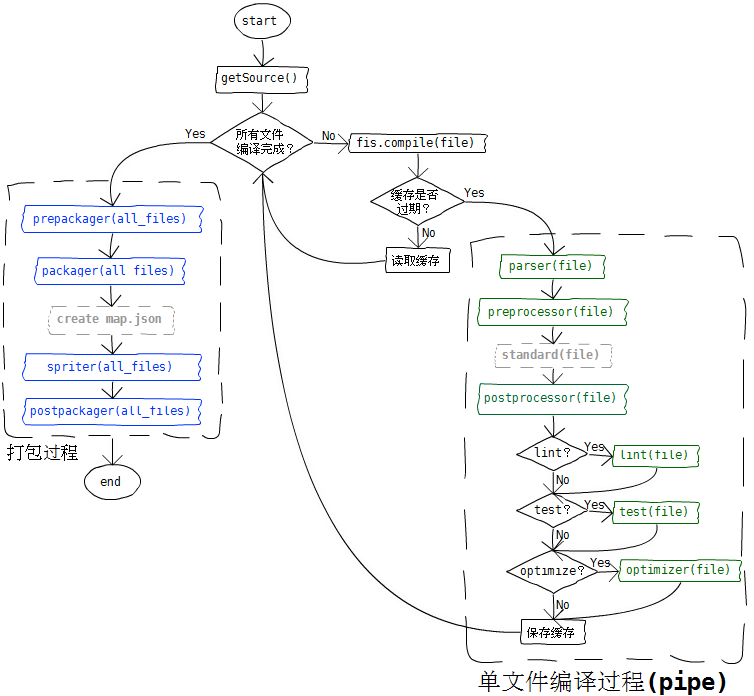
一个简单的例子:fis server open
开篇的描述可能比较抽象,下面我们来个实际的例子。通过这个简单的例子,我们可以对 FIS 的整体设计有个大致的印象。
下文以 fis server open 为例,逐步剖析 FIS 的整体设计。其实 FIS 比较精华的部分集中在 fis release 这个命令,不过 fis server 这个命令相对简单,更有助于我们从纷繁的细节中跳出来,窥探 FIS 的整体概貌。
假设我们已经安装了 FIS。好,打开控制台,输入下面命令,其实就是打开 FIS 的 server 目录
|
1 2 |
fis server open |
从 package.json 可以知道,此时调用了 fis/bin/fis,里面只有一行有效代码,调用 fis.cli.run()方法,同时将进程参数传进去。
|
1 2 3 4 |
<span class="comment">#!/usr/bin/env node</span> <span class="keyword">require</span>(<span class="string">'../fis.js'</span>).cli.run(process.argv); |
接下来看下../fis.js。代码结构非常清晰。注意,笔者将一些代码给去掉,避免长串的代码影响理解。同时在关键处加了简单的注释
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
<span class="comment">// 加载FIS内核</span> <span class="keyword">var</span> fis = module.exports = <span class="keyword">require</span>(<span class="string">'fis-kernel'</span>); <span class="comment">//项目默认配置</span> fis.config.merge({ <span class="comment">// ...</span> }); <span class="comment">//exports cli object</span> <span class="comment">// fis命令行相关的对象</span> fis.cli = {}; <span class="comment">// 工具的名字。在基于fis的二次解决方案中,一般会将名字覆盖</span> fis.cli.name = <span class="string">'fis'</span>; <span class="comment">//colors</span> <span class="comment">// 日志友好的需求</span> fis.cli.colors = <span class="keyword">require</span>(<span class="string">'colors'</span>); <span class="comment">//commander object</span> <span class="comment">// 其实最后就挂载了 commander 这个插件</span> fis.cli.commander = <span class="keyword">null</span>; <span class="comment">//package.json</span> <span class="comment">// 把package.json的信息读进来,后面会用到</span> fis.cli.info = fis.util.readJSON(__dirname + <span class="string">'/package.json'</span>); <span class="comment">//output help info</span> <span class="comment">// 打印帮助信息的API</span> fis.cli.help = <span class="keyword">function</span>(){ <span class="comment">// ...</span> }; <span class="comment">// 需要打印帮助信息的命令,在 fis.cli.help() 中遍历到。 如果有自定义命令,并且同样需要打印帮助信息,可以覆盖这个变量</span> fis.cli.help.commands = [ <span class="string">'release'</span>, <span class="string">'install'</span>, <span class="string">'server'</span> ]; <span class="comment">//output version info</span> <span class="comment">// 打印版本信息</span> fis.cli.version = <span class="keyword">function</span>(){ <span class="comment">// ...</span> }; <span class="comment">// 判断是否传入了某个参数(search)</span> <span class="keyword">function</span> hasArgv(argv, search){ <span class="comment">// ...</span> } <span class="comment">//run cli tools</span> <span class="comment">// 核心方法,构建的入口所在。接下来我们就重点分析下这个方法。假设我们跑的命令是 fis server open</span> <span class="comment">// 实际 process.argv为 [ 'node', '/usr/local/bin/fis', 'server', 'open' ]</span> <span class="comment">// 那么,argv[2] ==> 'server'</span> fis.cli.run = <span class="keyword">function</span>(argv){ <span class="comment">// ...</span> }; |
我们来看下笔者注释过的 fis.cli.run 的源码。
- 如果是
fis -h或者fis --help,打印帮助信息 - 如果是
fis -v或者fis --version,打印版本信息 - 其他情况:加载相关命令对应的插件,并执行命令,比如
fis-command-server
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
<span class="comment">//run cli tools</span> fis.cli.run = <span class="keyword">function</span>(argv){ fis.processCWD = process.cwd(); <span class="comment">// 当前构建的路径</span> <span class="keyword">if</span>(hasArgv(argv, <span class="string">'--no-color'</span>)){ <span class="comment">// 打印的命令行是否单色</span> fis.cli.colors.mode = <span class="string">'none'</span>; } <span class="keyword">var</span> first = argv[<span class="number">2</span>]; <span class="keyword">if</span>(argv.length < <span class="number">3</span> || first === <span class="string">'-h'</span> || first === <span class="string">'--help'</span>){ fis.cli.help(); <span class="comment">// 打印帮助信息</span> } <span class="keyword">else</span> <span class="keyword">if</span>(first === <span class="string">'-v'</span> || first === <span class="string">'--version'</span>){ fis.cli.version(); <span class="comment">// 打印版本信息</span> } <span class="keyword">else</span> <span class="keyword">if</span>(first[<span class="number">0</span>] === <span class="string">'-'</span>){ fis.cli.help(); <span class="comment">// 打印版本信息</span> } <span class="keyword">else</span> { <span class="comment">//register command</span> <span class="comment">// 加载命令对应的插件,这里特指 fis-command-server</span> <span class="keyword">var</span> commander = fis.cli.commander = <span class="keyword">require</span>(<span class="string">'commander'</span>); <span class="keyword">var</span> cmd = fis.<span class="keyword">require</span>(<span class="string">'command'</span>, argv[<span class="number">2</span>]); cmd.register( commander .command(cmd.name || first) .usage(cmd.usage) .description(cmd.desc) ); commander.parse(argv); <span class="comment">// 执行命令</span> } }; |
通过 fis.cli.run 的源码,我们可以看到,fis-command-xx 插件,都提供了 register 方法,在这个方法内完成命令的初始化。之后,通过 commander.parse(argv)来执行命令。
整个流程归纳如下:
- 用户输入 FIS 命令,如
fis server open - 解析命令,根据指令加载对应插件,如
fis-command-server - 执行命令
fis-command-server 源码
三个命令相关的插件中,fis-command-server 的代码比较简单,这里就通过它来大致介绍下。
根据惯例,同样是抽取一个超级精简版的 fis-command-server,这不影响我们对源码的理解
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
<span class="keyword">var</span> server = <span class="keyword">require</span>(<span class="string">'./lib/server.js'</span>); <span class="comment">// 依赖的基础库</span> <span class="comment">// 命令的配置属性,打印帮助信息的时候会用到</span> exports.name = <span class="string">'server'</span>; exports.usage = <span class="string">'<command> [options]'</span>; exports.desc = <span class="string">'launch a php-cgi server'</span>; <span class="comment">// 对外暴露的 register 方法,参数的参数为 fis.cli.command </span> exports.register = <span class="keyword">function</span>(commander) { <span class="comment">// 略过若干个函数</span> <span class="comment">// 命令的可选参数,格式参考 commander 插件的文档说明</span> commander .option(<span class="string">'-p, --port <int>'</span>, <span class="string">'server listen port'</span>, parseInt, process.env.FIS_SERVER_PORT || <span class="number">8080</span>) .action(<span class="keyword">function</span>(){ <span class="comment">// 当 command.parse(..)被调用时,就会进入这个回调方法。在这里根据fis server 的子命令执行具体的操作</span> <span class="comment">// ...</span> }); <span class="comment">// 注册子命令 fis server open</span> <span class="comment">// 同理,可以注册 fis server start 等子命令</span> commander .command(<span class="string">'open'</span>) .description(<span class="string">'open document root directory'</span>); }; |
好了,fis server open 就大致剖析到这里。只要熟悉 commander 这个插件,相信不难看懂上面的代码,这里就不多做展开了,有空也写篇科普文讲下 commander 的使用。
写在后面
如序言所说,欢迎交流探讨。如有错漏,请指出。
文章: casperchen


 推荐使用 Coding.net
推荐使用 Coding.net