为什么要使用数据结构和算法(程序=数据结构+算法)
数据结构是对在计算机内存中(有时在磁盘中)的数据的一种安排。包括数组、链表、栈、二叉树、哈希表等。
算法是对这些结构中的数据进行各种处理。比如,查找一条特殊的数据项或对数据进行排序。
举一个简单的索引卡的存储问题,每张卡片上写有某人的姓名、电话、住址等信息,可以想象成一本地址薄,那么当我们想要用计算机来处理的时候,问题来了:
- 如何在计算机内存中安放数据?
- 所用算法适用于 100 张卡片,很好,那 1000000 张呢?
- 所用算法能够快速插入和删除新的卡片吗?
- 能够快速查找某一张卡片吗?
- 如何将卡片按照字母进行排序呢?
对于传统的页面模型来说,数据的拉取+渲染模型如下:
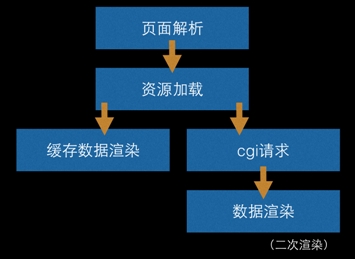
在页面的 head 部分,使用 jsonp 预拉取 cgi 资源,然后在资源加载完成之后,检查预拉取的数据是否已经返回,如果已返回,则直接用该数据渲染(避免了先用缓存数据渲染再用 cgi 数据渲染导致的二次刷新),否则才用缓存数据渲染。
有时候我们的代码有很多的条件判断,我们只能用 switch 语句来让代码更好看一点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function getDrink(type) { if (type === 'coke') { type = 'Coke'; } else if (type === 'pepsi') { type = 'Pepsi'; } else if (type === 'mountain dew') { type = 'Mountain Dew'; } else if (type === 'lemonade') { type = 'Lemonade'; } else if (type === 'fanta') { type = 'Fanta'; } else { // acts as our "default" type = 'Unknown drink!'; } return 'You\'ve picked a ' + type; } |
像上面介样子的代码,看起来是很头疼滴。而用 switch 语句,代码会更直观简洁。
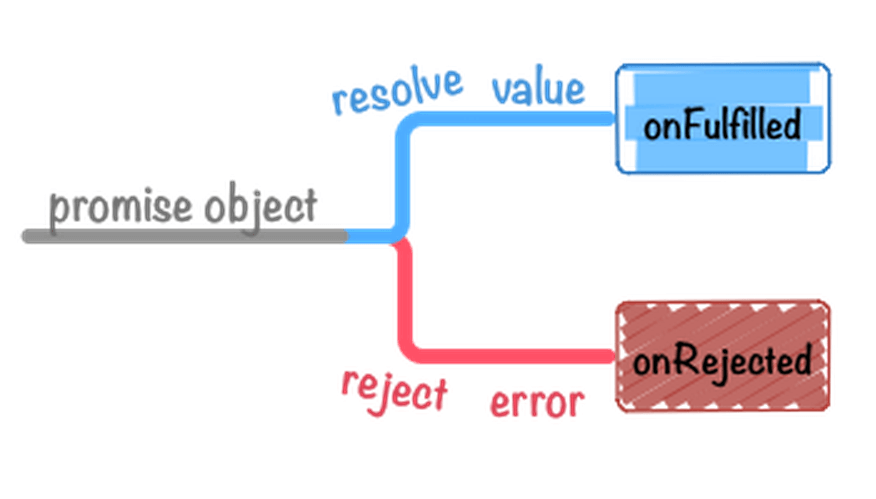
React Native 综述:
在 React Native 中,JavaScript 跟 Object-C 均有一个对应的中间件负责交互,源码中称为 bridge,它们通过 callback 的形式进行传参,通过参数配置来触发 OC 的控件,从而达到以 JavaScript 来控制 Native 的目的。
React Native 的设计理念:既拥有 Native 的用户体验、又保留 React 的开发效率。
React Native 的口号:Learn Once,Write Anywhere.
想做一个好用的在线编辑器,不管是地图编辑器、PPT 创作平台还是通过拖拽快速创建活动页面的编辑器等等,必然要给用户提供各种快捷的操作方法。如非常常用的复制粘贴功能。
举个例子,在 iPresst 创作平台,我们的作品在好几页都要用到同一张图片,总不能每次都点击上传一次图片吧?右键复制粘贴或者直接按快捷键无疑是最符合用户预期的操作方式,然而我们编辑器用到的元素一般比较特别,而且我们复制粘贴的时候经常要做一些特殊处理,此时我们就需要覆盖浏览器给我们提供的复制粘贴功能了。
(图片来源于互联网)
回调地狱
相信每一个 JS 程序员都曾被或者正在被回调地狱所折磨,特别是写过 Nodejs 代码的程序员。
|
1 2 3 4 5 6 7 8 9 |
asyncFun1(function(err, a) { // do something with a in function 1 asyncFun2(function(err, b) { // do something with b in function 2 asyncFun3(function(err, c) { // do something with c in function 3 }); }); }); |
React 简单介绍
先说 React 与 React Native
他们是真的亲戚,可不像 Java 和 Javascript 一样。
其实第一次看到 React 的语法我是拒绝的,因为这么丑的写法,你不能让我写我就写。
但当我发现 React Native 横空出世后,它学习一次到处运行的理念非常诱人。React Native 可以写出原生体验的 iOS/Android 应用?那不就多了一门装逼技能?所以我们调研小组试了一下,感觉 "Duang" 一下,很爽很舒服。写 React Native 需要两门基础技能:React 语法 和 iOS 基础知识。
很爽很舒服,索性就研究一下,算是入门。 了解之后发现,React 真是有另一番天地,值得学习。
接下来总结以下我对 React 的理解,分享给大家。
|
1 2 3 4 5 6 7 |
function* generateNaturalNumber() { var i = 0; while(i <= 100) { yield i; i++; } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
假设我们有以下目录结构: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/dir.png"><img class="alignnone size-full wp-image-6423" alt="dir" src="http://www.alloyteam.com/wp-content/uploads/2015/03/dir.png" width="330" height="258" /></a> 用户可能需要打包这个目录下的所有文件,或其中一些文件的组合(在定制组件的场景下)。 我们一般的做法是,提供一个页面,让用户进行选择,然后可以有两种做法: 1. 提交请求到服务器端,服务器对定制化的文件组合进行合并之后打包,返回给客户端进行下载。 2. 在客户端下载所需要的文件,自行进行合并之后打包,保存到本地。 在服务器端合并打包文件应该是比较常见的做法了,这里主要介绍一下浏览器端下载。 <!--more--> 我们先来了解一下 Blob 对象。 <strong>了解 Blob 对象</strong> 一个 Blob 对象一种原生数据的封装,只读,可以用于文件操作。基于 Blob 对象实现的有 File 对象。 创建一个 Blob 对象很简单,使用构造函数: |
|
1 2 3 4 5 6 7 8 9 10 11 |
// 参数 array 是 ArrayBuffer、ArrayBufferView、Blob、DOMString 对象的一种,或这些对象的混合。 // 参数 options 含两个属性: var array = ['<div id="myId"><a href="http://alloyteam.com">Alloyteam</a></div>'] var options = { type: '', // 默认为空,指定 array 内容的 MIME 类型 endings: 'transparent' // 默认为 'transparent', 指定遇到包含结束符 '/n' 的字符串如何写入 // 'native' 表示结束符转化为与当前用户的系统相关的字符表示, // 'transparent' 表示结束符直接存储到 Blob 中,不做转换。 }; var myBlob = new Blob(array, options); console.log(myBlob); |
|
1 2 3 4 5 6 7 |
创建了一个 Blob 实例后,它具有两个属性和一个方法 - 两个属性: - size - 大小,单位为字节 - type - MIME 类型,若构造时不指定则默认为空 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// DOMString 类型数据 var array = ['<div id="myId"><a href="http://alloyteam.com">Alloyteam</a></div>'] // 生成 Blob 对象并指定 MIME 类型 var myBlob = new Blob(array, {type: 'text/html'}); // 输出看看有啥 console.log(myBlob); // 大小,单位为字节 var size = myBlob.size; // MIME 类型,创建时不设置则为空 var type = myBlob.type; console.log('size: ', size); console.log('type: ', type); |
|
1 2 3 4 5 6 |
<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/c.png"><img class="alignnone size-full wp-image-6424" alt="c" src="http://www.alloyteam.com/wp-content/uploads/2015/03/c.png" width="820" height="132" /></a> - 一个 slice 方法 我们可以用这个方法在旧的 Blob 对象基础上切割出一个新的 Blob 对象, 这个方法和 Array.prototype.slice() 用法类似: |
|
1 2 3 4 5 6 7 8 9 10 |
// 切割, slice 后返回一个新的 blob 对象 // 第一个参数指定切割开始的位置 var myBlob2 = myBlob.slice(10); console.log(myBlob2); // 第二个参数指定切割结束的位置 var myBlob3 = myBlob.slice(10, 30); console.log(myBlob3); // 第三个参数可指定 MIME 类型,若不指定,则继承自 myBlob 的类型 |
|
1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/e.png"><img class="alignnone size-full wp-image-6425" alt="e" src="http://www.alloyteam.com/wp-content/uploads/2015/03/e.png" width="819" height="152" /></a> slice 方法能干啥? 当我们需要上传一个大文件时,可以用它来将一个文件切割为多个,然后分段上传到服务器。 <strong>使用 Blob 对象</strong> 创建 Blob 对象时,我们传入数据并指定 MIME 类型。 配合 FileReader 我们可以将 Blob 导出几种形式 - 导出为 ArrayBuffer, 定长的二进制数据 |
|
1 2 3 4 5 |
var myReader1 = new FileReader(); myReader1.onload = function () { console.log('readAsArrayBuffer: ', myReader1.result); }; myReader1.readAsArrayBuffer(myBlob); |
|
1 2 3 4 5 6 7 8 9 10 |
<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/g.png"><img class="alignnone size-full wp-image-6426" alt="g" src="http://www.alloyteam.com/wp-content/uploads/2015/03/g.png" width="815" height="35" /></a> 打印出来是空的,是因为 console.log 没法显示这种数据类型。 那我们看看这个 ArrayBuffer 的大小,发现它确实是存在的: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/h.png"><img class="alignnone size-full wp-image-6427" alt="h" src="http://www.alloyteam.com/wp-content/uploads/2015/03/h.png" width="601" height="145" /></a> - 导出为 Text, 纯文本 我们输入的是一个字符串且类型为 text/html, 那输出也自然是原来的字符串文本: |
|
1 2 3 4 5 |
var myReader2 = new FileReader(); myReader2.onload = function () { console.log('readAsText: ', myReader2.result); }; myReader2.readAsText(myBlob); |
|
1 2 3 |
<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/j.png"><img class="alignnone size-full wp-image-6428" alt="j" src="http://www.alloyteam.com/wp-content/uploads/2015/03/j.png" width="822" height="37" /></a> - 导出为 DataURL |
|
1 2 3 4 5 |
var myReader3 = new FileReader(); myReader3.onload = function () { console.log('readAsDataURL: ', myReader3.result); }; myReader3.readAsDataURL(myBlob); |
|
1 2 3 4 5 6 7 8 |
<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/n.png"><img class="alignnone size-full wp-image-6429" alt="n" src="http://www.alloyteam.com/wp-content/uploads/2015/03/n.png" width="819" height="49" /></a> 我们熟悉的小图片转化为内嵌的 base64 则可以使用 DataURL 来处理 - 导出为 ObjectURL 形式 与 DataURL 不同的是,ObjectURL 创建的是一个躺在内存里的 DOMString, 它不像 DataURL 编码后数据保存到那一串字符串里,DOMString 依赖浏览器环境才能显示 |
|
1 2 3 4 |
var array = ['<div id="myId"><a href="http://alloyteam.com">Alloyteam</a></div>'] var myBlob = new Blob(array, {type: 'text/html'}); var url = URL.createObjectURL(myBlob); console.log(url); |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/p.png"><img class="alignnone size-full wp-image-6430" alt="p" src="http://www.alloyteam.com/wp-content/uploads/2015/03/p.png" width="817" height="50" /></a> 我们得到一个以 'blob:' 开头的串,如果我们把它复制到浏览器地址栏中回车,将会发现: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/q.png"><img class="alignnone size-full wp-image-6431" alt="q" src="http://www.alloyteam.com/wp-content/uploads/2015/03/q.png" width="822" height="185" /></a> 这有什么用呢?下载文件! 比如我们需要下载这个 myBlob 的话,可以配合 a 标签的 download 属性, 将 URL.createObjectURL 返回的数据复制给 a 标签的 href 属性, 再给 a 标签添加 download 属性,则触发点击这个 a 标签后,将会下载文件。 <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/r.png"><img class="alignnone size-full wp-image-6432" alt="r" src="http://www.alloyteam.com/wp-content/uploads/2015/03/r.png" width="1080" height="840" /></a> 若需要指定下载的名字,则给 download 属性赋值,如 |
|
1 |
<a href="blob:xxx" download="myName">下载</a> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
dataURL 和 objectURL 有啥区别呢?<a href="http://www.alloyteam.com/wp-content/uploads/2015/03/s.png"> <img class="alignnone size-full wp-image-6433" alt="s" src="http://www.alloyteam.com/wp-content/uploads/2015/03/s.png" width="1012" height="526" /> </a> 刷新页面会发现 dataURL 不再变化,而 objectURL 会不断变化: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/t.png"><img class="alignnone size-full wp-image-6434" alt="t" src="http://www.alloyteam.com/wp-content/uploads/2015/03/t.png" width="1015" height="526" /></a> 原因是,dataURL 创建的是实际的数据,而 objectURL 既然是 DOMString,依赖浏览器环境, 当这个页面一旦关闭(销毁),objectURL 将从内存中删除。 我们可以验证一下: 在浏览器地址栏输入 objectURL: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/u.png"><img class="alignnone size-full wp-image-6435" alt="u" src="http://www.alloyteam.com/wp-content/uploads/2015/03/u.png" width="755" height="189" /></a> 当我们把创建 objectURL 的页面关闭后,再刷新会发现: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/v.png"><img class="alignnone size-full wp-image-6436" alt="v" src="http://www.alloyteam.com/wp-content/uploads/2015/03/v.png" width="812" height="171" /></a> 数据不见了!因为浏览器页面关闭后回收了这段内存,那这段 blob: 引用的 DOMString 不再存在。 当然我们也可以手动调用 URL.revokeObjectURL() 的方式来回收。 (当多次调用 URL.createObjectURL 用完后,即时释放内存很重要) 在浏览器地址栏输入 dataURL, 发现 dataURL 是真实的数据,不会随页面关闭而消失: <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/w.png"><img class="alignnone size-full wp-image-6437" alt="w" src="http://www.alloyteam.com/wp-content/uploads/2015/03/w.png" width="1137" height="186" /></a> dataURL 是真实的数据,可以用于对小图片进行编码等操作; objectURL 可以将一个文件转化为 URL 的形式,让我们获得操作文件的能力。 <strong>服务器端与客户端下载文件</strong> 介绍了那么多 Blob, 是不是跑题了。。。 <strong>服务器端下载文件</strong> 服务器端下载文件主要有几步: 1. 根据请求将用户所需要的文件添加到一个临时文件夹 download/xxx 2. 将临时文件夹压缩 download/xxx.zip 3. 将压缩包返回 res.sendFile('download/xxx.zip') 4. 删除临时文件 fs.unlink('download/xxx.zip'); 对于不同的用户,有不同的定制化要求时,生成临时文件夹也必须唯一,所以需要生成唯一的文件夹名。 压缩包生成后,立即删除临时文件夹,并在压缩包成功传回客户端后,立即删除压缩包文件,以节省硬盘空间。 <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/x.png"><img class="alignnone size-full wp-image-6438" alt="x" src="http://www.alloyteam.com/wp-content/uploads/2015/03/x.png" width="425" height="86" /></a> 在这里对每个定制化的请求返回一个压缩包响应后,立即删除了临时文件。 <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/y.png"><img class="alignnone size-full wp-image-6439" alt="y" src="http://www.alloyteam.com/wp-content/uploads/2015/03/y.png" width="865" height="597" /></a> 还有一种做法是对压缩包进行缓存,若发现缓存中存在对应的压缩包,则不再新建。 前者可以立即释放硬盘空间,后者则可以节省计算,各有利弊。 <strong>浏览器端下载文件</strong> 浏览器端下载文件主要有几步: 1. 使用 AJAX 去下载所需要的文件 2. 使用 Blob 对象对文件内容进行存储 3. 使用 JSZip.js 或其他 zip 类库进行压缩 4. 使用 FileSaver.js 或其他 file 接口保存文件 <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/z.png"><img class="alignnone size-full wp-image-6440" alt="z" src="http://www.alloyteam.com/wp-content/uploads/2015/03/z.png" width="865" height="229" /></a> ajax 异步下载文件,如何得知所有文件下载完成呢? 可以自己维护一个计数器,或者使用 Promise 吧! <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/z-a.png"><img class="alignnone size-full wp-image-6441" alt="z-a" src="http://www.alloyteam.com/wp-content/uploads/2015/03/z-a.png" width="790" height="590" /></a> 我这里使用了以下优秀类库 - [jsZip](https://stuk.github.io/jszip/) 用于在浏览器端压缩文件 - [FileSaver](https://github.com/eligrey/FileSaver.js) 用于将文件保存到本地 - [bluebird](https://github.com/petkaantonov/bluebird) 用于控制异步 AJAX 获取文件 <strong>服务器端与浏览器端下载文件的对比</strong> <a href="http://www.alloyteam.com/wp-content/uploads/2015/03/z-b.png"><img class="alignnone size-full wp-image-6442" alt="z-b" src="http://www.alloyteam.com/wp-content/uploads/2015/03/z-b.png" width="862" height="473" /> </a> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
1. 环境依赖: 在服务器端需要部署环境,而对于一些简单的文件合并, 我们可能就只是希望放在 gh-pages 上就能跑, 那在浏览器端进行文件合并与压缩则比较轻量。 2. 可靠程度: 服务器是直接返回一个压缩包, 而浏览器则需要自行下载多个文件后合并, 而其中的文件传输可能会发生错误。 3. 临时文件: 服务器对于不同的定制化请求都会产生临时文件 (是可以把临时文件放到内存里,但是内存比硬盘还贵还小,成本会比较高), 若同一时间定制的请求过多(比如有人恶意 DDOS?), 那么硬盘将会撑满,就只能把躺在硬盘里的苍老师删掉了吧 - -! 而对于浏览器而言,我们可以把文件存放到不同的 CDN 中,加快文件的传输, 并且临时文件存到了用户的硬盘里,就不用删掉服务器里的苍老师了。 4. 缓存功能: 服务器可以做缓存以减少计算,但带来了硬盘的开销。 5. 传输文件: 服务器响应一个请求返回一个压缩包,可以经过 gzip 压缩返回, 而浏览器则要下载多个文件多个 HTTP 请求响应, 但同时可以利用 cdn 进行下载,加快速度。 6. 兼容性: 你懂的。 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<strong>示例代码 </strong> - <a href="http://laispace.github.io/downloadFilesInBrowserAndServer/public/">客户端下载文件</a> - <a href="http://laispace.github.io/downloadFilesInBrowserAndServer/createObjectURL.html">createObjectURL.html</a> - <a href="http://laispace.github.io/downloadFilesInBrowserAndServer/DataURL&ObjectURL.html">DataURL&ObjectURL.html</a> - <a style="font-weight: bold;" href="https://github.com/laispace/downloadFilesInBrowserAndServer">所有代码</a> <strong>参考链接</strong> - <a href="https://developer.mozilla.org/en-US/docs/Web/API/Blob">[Blob](https://developer.mozilla.org/en-US/docs/Web/API/Blob)</a> - <a href="http://en.wikipedia.org/wiki/MIME">[MIME](http://en.wikipedia.org/wiki/MIME)</a> - <a href="https://developer.mozilla.org/en-US/docs/Web/API/File">[File](https://developer.mozilla.org/en-US/docs/Web/API/File)</a> - <a href="https://developer.mozilla.org/en-US/docs/Web/API/FileList">[FileList](https://developer.mozilla.org/en-US/docs/Web/API/FileList)</a> - <a href="https://developer.mozilla.org/en-US/docs/Web/API/FileReader">[FileReader](https://developer.mozilla.org/en-US/docs/Web/API/FileReader)</a> - <a href="https://developer.mozilla.org/en-US/docs/Web/API/URL/createObjectURL">[createObjectURL](https://developer.mozilla.org/en-US/docs/Web/API/URL/createObjectURL)</a> - <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer">[ArrayBuffer](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer)</a> - <a href="https://stuk.github.io/jszip/">[jsZip](https://stuk.github.io/jszip/)</a> - <a href="https://github.com/eligrey/FileSaver.js">[FileSaver](https://github.com/eligrey/FileSaver.js)</a> - <a href="https://github.com/petkaantonov/bluebird">[bluebird](https://github.com/petkaantonov/bluebird) </a> |


 推荐使用 Coding.net
推荐使用 Coding.net